1 条题解
-
0
自动搬运
来自洛谷,原作者为

Arahc
qwqaqwq搬运于
2025-08-24 22:32:26,当前版本为作者最后更新于2021-07-12 08:10:42,作者可能在搬运后再次修改,您可在原文处查看最新版自动搬运只会搬运当前题目点赞数最高的题解,您可前往洛谷题解查看更多
以下是正文
题意简述
给定一个 的 矩阵,定义一个 H 形为一个长得像 H (感性理解,具体见题目描述)的图形,求有几个由 组成的 H 形。
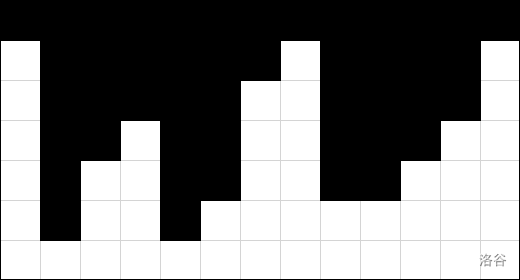
例如下图图示(白色为 ,黑色为 ),一共有 个 H 形,这也告诉我们 H 形是可以互相有重叠甚至有包含关系的(但不同的 H 形不会完全恰好重合)。

题目分析
考虑到 。需要设计一个 (或带一个 log )的算法,直接暴力枚举四元组中的任意两个都无法完成,需要找到 H 形中的一个特性。
首先考虑是否可以枚举 H 的竖线(每个 H 有两个竖线,这里考虑左侧)。考场上糊了一个想法:记录每一条竖着的白线,以及每一个点往右可以到达的最近的点,图示情况可以后续推乘法原理加法原理的式子做到 。随后很快发现了不可行,因为即使我记录了每一个点向右最多可以到达哪些点,整体判断一个 H 的两条竖线是否一一对应还是 的。
除此之外,即使两个 竖线部分是包含关系,也不一定代表横线部分重合,例如:


这两种情况都无法简单地区分,例如左侧这种,高度为 的 H 和高度为 的 H 竖线部分共线但是横线部分不共线。右侧这种情况说明不能只记录每一个白格子右侧第一个白格子,因为两个 H 可能只有一个竖线共线。
因此考虑竖线的情况比较难处理,又因为 H 里面只有一条横线,来考虑横线的情况。
对于任何一个 H,显然横线的两端刚好是竖线的中点。因此选择一个横线的两个端点,向上和向下延伸同样的高度(且都是白格子),就一定可以得出一个 H。
基于这种思想我们记录每一个格子向上最多可以延伸多少个格子,向下最多可以延伸多少个格子。
而显然一个横线两端的点向上和向下延伸的白格子应该是相同的,因此对于某一个格子而言,向上延伸和向下延伸的格子数取最小值,才会是以它为横线的一个端点,可能形成的高度最大的 H 的高度的一半。
(也就是 H 的最大高度为 )。
// a 数组为输入的 0-1 矩阵 for(register int j=1;j<=m;++j){ for(register int i=1;i<=n;++i){ if(a[i][j]) up[i][j]=0; else up[i][j]=up[i-1][j]+1; }// 向上 for(register int i=n;i>=1;--i){ if(a[i][j]) dn[i][j]=0; else dn[i][j]=dn[i+1][j]+1; }// 向下 for(register int i=1;i<=n;++i) for(register int j=1;j<=m;++j) s[i][j]=min(up[i][j],dn[i][j]); // 取 min // 注意 H 的真正高度为 s[i][j]*2-1 // 因为中间那一个白格子在这里也算进去了 }通过放在最前面的第一张图,我们知道同一个横线上可能出现多个大小不同的 H。假设每个横线上有若干白格子。我们发现……
(注:下图的白格子高度指的是最底下一行的横线的 )
第 个可以和第 个匹配出一个 H,第 个可以和第 个匹配成一个 H……
发现高度小的一定可以和高度大于等于它的匹配。且按照这种方法匹配得出的 H 不重不漏。
因此可以每次取出一段白色的横线(设长度为 ),取出横线上每个点的 值,如果我们从小到大排个序,就会发现第 个一定可以和第 个匹配,一共有 个 H。
每一段白色的横线取出并逐个计算,累加答案。由于有一个排序,最多有 个长度为 的横线,因此总的复杂度为 的,可过。且只要有黑色的格子这东西就不会卡满。因此效率是非常可观的。
主要处理的部分:
int i=1;j=1; while(i<n){ while(a[i][j] && j<=m) ++j; if(j>m){ // 避免 j 越界 ++i,j=1; continue; } tot=0; while(!a[i][j] && j<=m){ // 不要忘记 j<=m,会越界 p[++tot]=s[i][j]-1; // 这里要-1(参见上面预处理代码注释) ++j; } std::sort(p+1,p+1+tot); // 小到大排序 for(register int k=1;k<=tot;++k) ans+=p[k]*(tot-k); // 对于每一个 k 一共 tot-k 个 H 可以匹配 if(j>m){ // 越界判断 ++i,j=1; continue; } }告诫后人
考场上本来用的优先队列
priority_queue,惨遭 TLE,个人觉得可能是因为其每次插入和删除都是 ,也就是两个 ,因此整体带了一个常数(再加上 STL 可能还有常数)。而sort是一个 ,后续处理是 的。整体常数小一些。如果用优先队列 TLE 的话,如果算法没有错误可以改成直接存数组里再排序,说不定就 A 了呢~
- 1