1 条题解
-
0
自动搬运
来自洛谷,原作者为

jjsnam
I'm no good at goodbyes.搬运于
2025-08-24 21:50:56,当前版本为作者最后更新于2022-08-30 22:02:53,作者可能在搬运后再次修改,您可在原文处查看最新版自动搬运只会搬运当前题目点赞数最高的题解,您可前往洛谷题解查看更多
以下是正文
写在前面
Update on 2023.7.6:感谢 @yizhiming 指出代码有一处锅。
这道题真的是神毒瘤题。质量很好,毒瘤主要是题解写的都太简略了,就好像第一问默认大家都会一样,然后各种做法层出不穷,也不讲一讲直接放代码。反正我作为一个阅读者体验非常不好。调了一天终于弄懂了,来补一篇正解的详细做法。
前置知识
- 倍增
- 贪心
- STL:
set用法 - 离散化
题目描述(戳这里查看原题)
-
给定 个线段,编号 到 。
-
求把这些线段放在数轴上,在两两不相交的情况下最多能放多少个,记作 。
-
在满足总数为 的情况下,使数轴上的线段的编号组成的集合(排序后)字典序最小。输出此时的集合 。
-
。
正文
把刚才的形象化题意再剥离一下,第一问就是求最大线段覆盖,第二问就是让使用的线段编号尽可能小。
尝试
第一问的求法很多,贪心或者 DP 都是可以的,我们看看第二问更适合哪种方法就用哪种方法。
一般与字典序有关的题目,DP 是首选,贪心思维难度则要更大一些。所以我们先考虑 DP。
例如,我们设 表示以第 个线段为首后能插入的最多线段数。我们将读入线段标记编号后按左端点排序,存入结构体 中。那么对于 转移:
这样就是一个区间最大值转移问题,可以用线段树优化,时间复杂度 。
但是别忘了还有第二问。注意最后的集合是排完序字典序最小,而不是按线段值的大小加入的顺序字典序最小,所以我们需要记录整个线段集合。我没有想到什么好方法,直接变成了树套树,时间复杂度 。而且空间也爆炸,这是一个50分 记录。
因此,DP 不是一个好选择。
分析
那我们再考虑贪心。通过刚才的思考,我们发现第二问是更恶心的,所以我们假设第一问已经求得了最大的 。第二问如何求呢?
可以想到,按编号从小到大依次确定插入的线段,如果满足条件则一定是最优的。接下来考虑条件是什么。
我们把满足最优解的线段集合记作 (任意时刻满足 且 可以为 ),我们考虑加入一个新的线段 。那么,首先要满足的是插入后一定有办法使最后集合里的线段总数仍然是 。如果不满足这个条件,无论编号多小都不能再贪了,因为不满足第一问的条件。
插入这个线段后可能对答案有影响的最大区间如何找?假设我们在 中找到 的前驱 和后继 。那么它插入后对其前驱即前驱之前的区间的最优放置方案没有影响;同理,对于后继即后继之后的区间也没有影响。有影响的是前驱和后继之间的那段区间,如下图:
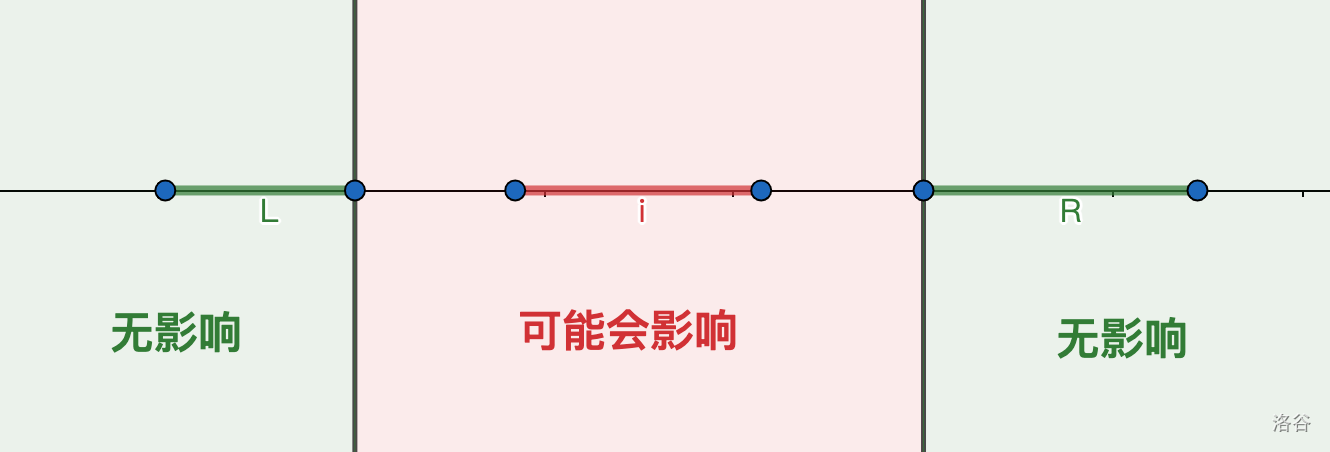
用数学方法表示,最多可能有影响的区间是 。
接下来考虑条件如何满足。对于任意一个确定的区间,我们最多能放置的线段数都是可以确定的,记作 。为了使最后整个数轴放的线段最多,贪心的思路就是使每个子区间都达到最优放置方案,也就是每个子区间的 和就是最后的 。可以证明这样贪心是正确的。
那么对于可能有影响的区间,原来最多能放置的线段数记作 ,在这个区间里确定了某个线段后,区间再次被分成 部分,即加入的线段左边,加入的线段和加入的线段右边(对应 、、)。而且中间的 值一定是 (钦定只放加入的线段)。
如果我们加入这条新的线段可以不使答案变差,也就是加入后划分出的三个子区间最多能放的线段数之和还是大区间原来最多能放的数量,那么加入这条线段后总的答案不会变劣,还是 ;又因为从小到大枚举编号,此时加入这条线段一定是满足条件下编号最小的,也就满足了排序后线段集合字典序最小的要求,可以作为第二问的答案。
最终满足的条件形象化写出来是这样的:
$$ Pre=f(seg_L.r+1,seg_i.l-1)+f(seg_i.r+1, seg_R.l-1)+1 $$细节与实现
大致思路理清了,我们来考虑一下具体怎么做,毕竟刚才跳过了很多。
-
首先考虑 如何求。
每个线段左右端点值的大小最大可以达到 ,所以我们先对数据离散化,这样就最多只有 个有用的数点。
然而,如果我们处理出所有 的时间复杂度是 的。考虑优化。这些有用的数点对应的线段都是一定的,而且根据贪心每个线段之后连接的最优线段也是可以确定的,所以我们尝试倍增。 表示数点 往右选 个线段后到达的最小右端点(这样就满足了每次都是选最优线段)。
但是一个数点的含义可能很复杂,比如这个点既是某些线段的右端点,也是某些线段的左端点,因而需要考虑很多情况,每个数点右侧第一个最优线段的选择不好实现。 考虑到每个线段的下一个线段是可以贪心求出的,我们可以对 的定义略加修改。定义 表示线段 往右再选 个线段后到达的使右端点最小的线段的编号。同样,我们将 定义为从线段 往后选线段,使最后一个线段的右端点不超过 ,最多选多少个。
注意这样调用 函数是不包括一开始的线段 的。当然包括也可以,但是不包括更方便一些,尤其对于之后第二问的操作,我们分成三段后前后两段的 值在求的时候以加入线段的前驱和加入的线段作为起点即可。而包括 则还要以前驱后第一个最优线段作为前段的起点,多了一步,后段同理。
这样 可以通过下面的代码求出:
int f(int st, int r){ int res = 0; for (int k = Log2; k >= 0; k --){ if (seg[ne[st][k]].r <= r){ res += (1 << k), st = ne[st][k]; } } return res; } -
如何求?
根据一般倍增的经验,我们只需要求 ,也就是每条线段下一个最优线段,然后循环 暴力跳递推即可。
现在考虑如何求 。即对于每个线段,我们要找到左端点大于当前线段右端点且右端点尽可能小的线段。如果我们将所有线段按左端点为关键字排序,则最后变成了一个 RMQ 问题。我这里使用的是后缀最小值倒推的方法。
因为有用数点总数是 级别的,所以定义 表示离散化后数点 及其右侧的所有左端点不小于 的线段最小的右端点。 则表示使右端点最小的这个线段的编号。
递推时先赋值 (这里的 是遍历每个线段)。然后倒推,对于每个数点 ,如果 ,则用 来更新 的 和 值。
-
再来考虑求第二问时的前驱后继如何找。我们可以通过 STL 中的 set 维护 中的数点(每个线段的左右端点),这样就可以通过 set 内置的
upper_bound函数求出前驱后继了。具体地,在记录数点时可以同时记录每个数点对应的线段(因为集合里的线段不可能重合,所以每个点的含义有且只有一个)。先用upper_bound函数求出第一个大于新加入线段右端点的线段的编号,此时迭代器指针前移 就是第一个小于线段左端点的编号。但这样有一个问题,如果加入的线段与集合中某个线段重合怎么办?根据定义不能包含两者,而根据贪心顺序集合里的线段的编号一定比新加入的线段编号小,故这个新的线段不论满不满足条件都要舍弃。可以通过判断新加入的线段左右端点
upper_bound值是否相等确定是否有与集合内线段重合的情况。 -
不管是用 set 维护时前两次加入线段找前驱后继,还是在递推 倍增数组跳出所有线段后应到达的位置,都需要边界处理。为了方便,我们可以构建两个“哨兵线段”。一个编号为 ,左右端点都是极小值;一个编号为 ,左右端点都是极大值。这样的话 ,再次递推时不会 RE;在求答案前先加入两个哨兵线段,这样新加入线段时不会出现返回迭代器为空的情况。码量减少了很多。
-
话说了这么多,别忘了 还没解决。但有了“哨兵线段”后,我们可以从极小哨兵开始,取到极大哨兵的左端点(不包括),这样就是最大区间的最优情况。即
m = f(0, inf-1)。
最终的时间复杂度是 。瓶颈在于倍增和 set 及其常数。
代码
变量名与文章中的数组无异,必要注释已添加。代码略长,建议自己写一遍。
#include <iostream> #include <algorithm> #include <cstring> #include <set> using namespace std; const int maxn = 200005; const int inf = 1e9; struct Segment{ int l, r, id; }seg[maxn]; int Disc[maxn << 1], cnt; //离散化 int n, Log2; int ne[maxn][18], Mn[maxn << 1], pos[maxn << 1]; struct Node{ int v, id; bool operator < (const Node &b) const{ return v < b.v; } }; set<Node> s; bool cmp1(Segment a, Segment b){ return a.l < b.l; } bool cmp2(Segment a, Segment b){ return a.id < b.id; } int getMx(int st, int r){ int res = 0; for (int k = Log2; k >= 0; k --){ if (seg[ne[st][k]].r <= r){ res += (1 << k), st = ne[st][k]; } } return res; } int main(){ ios::sync_with_stdio(false); cin.tie(0), cout.tie(0); cin >> n; while ((1 << Log2) <= n) Log2 ++; Log2 --; //floor(log_2{n}) for (int i = 1, l, r; i <= n; i ++){ cin >> l >> r; Disc[++ cnt] = l, Disc[++ cnt] = r; seg[i] = (Segment){l, r, i}; } /* 离散化 */ sort(Disc+1, Disc+cnt+1); cnt = unique(Disc+1, Disc+cnt+1) - Disc - 1; for (int i = 1; i <= n; i ++){ seg[i].l = lower_bound(Disc+1, Disc+cnt+1, seg[i].l) - Disc; seg[i].r = lower_bound(Disc+1, Disc+cnt+1, seg[i].r) - Disc; } /* 处理倍增 */ sort(seg+1, seg+n+1, cmp1); seg[n+1] = (Segment){inf, inf, n+1}, seg[0] = (Segment){-inf, -inf, 0}; /* 先递推后缀最小值 */ memset(Mn, 0x3f, sizeof Mn); Mn[cnt+1] = cnt+1, pos[cnt+1] = n+1; for (int i = n; i > 0; i --){ if (Mn[seg[i].l] > seg[i].r){ Mn[seg[i].l] = seg[i].r, pos[seg[i].l] = seg[i].id; } } for (int i = cnt; i > 0; i --){ if (Mn[i] > Mn[i+1]){ Mn[i] = Mn[i+1], pos[i] = pos[i+1]; } } /* 更新倍增数组 */ ne[n+1][0] = n+1; for (int i = 1; i <= n; i ++){ ne[seg[i].id][0] = pos[seg[i].r+1]; } int st = n+1; for (int i = 1; i <= n; i ++){ if (seg[i].r < seg[st].r) st = i; } ne[0][0] = seg[st].id; for (int k = 1; k <= Log2; k ++){ for (int i = 0; i <= n + 1; i ++){ ne[i][k] = ne[ne[i][k-1]][k-1]; } } /* 注意!统计答案前应该先还原线段排列,因为ne存的是原始线段的编号 */ sort(seg+1, seg+n+1, cmp2); /* 计算M */ int M = getMx(0, inf-1); cout << M << endl; /* 添加“哨兵” */ s.insert((Node){-inf, 0}), s.insert((Node){inf, n+1}); /* 贪心模拟 */ set<Node>::iterator it; for (int i = 1; i <= n; i ++){ if (s.upper_bound((Node){seg[i].l, seg[i].id}) != s.upper_bound((Node){seg[i].r, seg[i].id})) continue; //有重合 it = s.upper_bound((Node){seg[i].r, seg[i].id}); Node L = *it; it --; Node R = *it; if (getMx(R.id, seg[i].l-1) + getMx(i, L.v-1) + 1 != getMx(R.id, L.v-1)) continue; cout << i << ' '; s.insert((Node){seg[i].l, seg[i].id}), s.insert((Node){seg[i].r, seg[i].id}); } cout << endl; return 0; }总结
这道题确实考点很多,另外我觉得贪心真的很难。
主要是这道题的题解区太乱了,高赞的都是囫囵吞枣讲一堆,真正有点价值又被排到了后面,所以我才想写一篇完整思路,不过篇幅略长。
谢谢观看!
- 1