1 条题解
-
0
自动搬运
来自洛谷,原作者为

yemuzhe
烟波里成灰 也去得完美搬运于
2025-08-24 22:47:52,当前版本为作者最后更新于2023-07-31 21:49:35,作者可能在搬运后再次修改,您可在原文处查看最新版自动搬运只会搬运当前题目点赞数最高的题解,您可前往洛谷题解查看更多
以下是正文
此题解篇幅太长,请谨慎观看!题目大意
-
有一个大小为 的牌堆 ,牌堆中的数均为 ,且每个数恰好出现 次。
-
刚开始有两个空栈。可以进行 次操作,有两种操作:
-
可以把牌堆顶上的数放入一个栈中,如果该栈最上方的两个数相同,则自动消去这两个数。
-
如果两个栈顶的数相同,则可以消去这两个数。
-
-
构造一种操作方案,使得所有数都被消去。
-
且 为偶数。
解题思路
这题可用区间 dp 解决。
容易发现,第一种操作的后半句没什么用,因为可以改写成第二种操作来实现。
于是我们把相同的两个数放入不同的栈中,也避免了第一种操作的自动消除。
考虑牌堆中的一段区间 。内部可以消去的肯定要消去,剩下的是不能消去的数,且按原牌堆顺序排列。
如图:(图中一种颜色的球代表一个数)
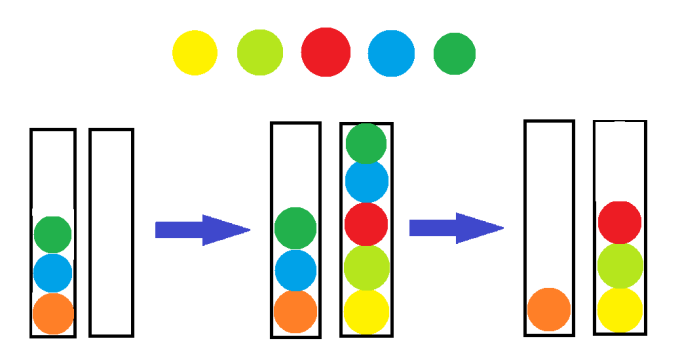
当然,也不一定像这样所有一起加入后再消除。
在 dp 时我们枚举 内最后消去的数(可能一个或两个),然后分段处理。
我们把 中能和 中的数配对的数称为「有用的数」。
这里有一条非常重要的性质:
「有用的数」一定都(要)堆在同一个栈的最顶部。
我们把这个栈称为「有用的栈」。如果没有「有用的数」则认为两个栈都是「有用的栈」。
这条性质的证明将会在「区间 dp」部分的末尾给出。请读者时刻牢记这一性质。
Part 1:预处理
在 dp 之前,我们需要预处理几个数组:。
-
数组
记录的是值为 的另一个数的位置。可以用一个 数组记录 上一次出现的位置处理。
for (int i = 1; i <= n; i ++) { // 如果 A[i] 已经出现过,那么那么令 p[上一次出现的位置] = i 且 p[i] = 上一次出现的位置 if (l[a[i]]) p[l[a[i]]] = i, p[i] = l[a[i]]; l[a[i]] = i; // 用当前位置更新 } -
数组
表示对于 ,最前面的满足 的 。
初始化 (即无穷大),易得递推式 $lx _ {l, r} = \begin {cases} lx _ {l + 1, r} & (p _ l \le r) \\ \min \{lx _ {l + 1, r}, l\} & (p _ l > r) \end {cases}$。
这个函数可以用来判断 内的数是否可以全部消除(即 是否大于 )。
-
数组
表示对于 ,最后面的满足 的 。
初始化 (即负无穷大),易得递推式 $ry _ {l, r} = \begin {cases} lx _ {l, r - 1} & (p _ r \ge l) \\ \min \{lx _ {l, r - 1}, r\} & (p _ r < l) \end {cases}$。
可以在 dp 时顺便处理,省去两维(就变成变量了)。
-
数组
表示对于 ,最前面的 。
初始化 ,易得递推式 。
可以在 dp 时顺便处理,省去第一维(如果不是还要预处理 数组还可省去第二维)。
-
数组
表示对于 ,最前面的满足 的 。
考虑用树状数组实现。注意这里的树状数组的循环顺序有些不同,用来实现后缀查询。
加入时只加 的。在 位置加入 。
查询时 这一段区间的最小值,也可以查询 。
可以在 dp 时顺便处理,省去第一维。
void modify (int p, int c) // 单点修改(其实是加入) { for (; p; p &= p - 1) tr[p] = min (tr[p], c); return ; } int ask (int p) // 区间(后缀)求最小值 { int res = inf; for (; p <= n; p += p & -p) res = min (res, tr[p]); return res; } // int main () for (int l = n; l; l --) { // ... memset (tr, 0x3f, sizeof tr); for (int r = n; r >= l; r --) { ly[r] = ask (xl[r]); // 询问满足条件的最小 i if (p[r] < l) modify (p[r], r); // 加入当前 r } // ... } -
数组
表示对于 ,最后面的 。
初始化 ,易得递推式 。
可以在 dp 时顺便处理,省去两维(就变成变量了)。
这样我们就完成了所有的预处理。
Part 2:区间 dp
状态设计
记 为当一个栈是「有用的栈」时,能否删完 内配对的部分并把剩下的堆在另一个栈。
同理记 为当一个栈是「有用的栈」时,能否删完 内配对的部分并把剩下的堆在同一个栈。
考虑到可能没有剩余的,记 为当一个栈是「有用的栈」时,能否删完 这部分。
容易发现 其实是 和 共同的特殊情况。
注意「状态转移」部分中分界点的同 / 另一个栈是相对整个区间而言,而子区间的同 / 另一个栈是对子区间而言。
由于题目还要求具体方案,需要存三个数组 ,来记录转移的信息(具体见「状态转移」部分)。
根据「状态转移」部分可知,最终答案即 的过程仅与 有关,故只设计设三种状态即可。
初始化
初始化 $f _ {i + 1, i} = g _ {i + 1, i} = both _ {i + 1, i} = 0$()即可。
状态转移
-
第一种:
概念
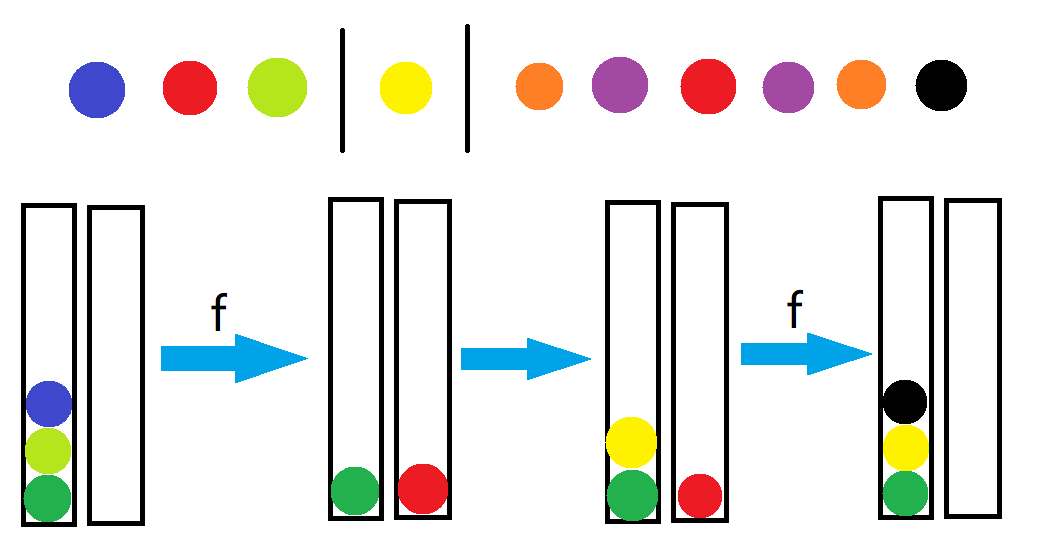
如上图,我们选择最前面的满足 的 即 ,然后把这个序列分成 、 和 三段。
对于 这段,把它们放进另一个栈(右边)。
对于 ,把它放进同一个栈(左边),它不会产生任何消除(和它配对的在 后面)。
对于 ,把它们放进另一个栈(这时是左边),这时它们会把 这部分剩下的全部消掉。
为什么这时候另一个栈是左边呢?因为左边的栈已经被 堵住了,相当于是空栈(没用),但右边的栈很可能是「有用的栈」。
这样我们就不会在另一个栈(右边)剩东西,从而实现了 的转移。
为什么 一定是最后消除的呢?
如果分界点为 ,那么 的剩余部分都会叠在 上面(堵住了),而 没有剩余;
如果分界点不为 ,那么 就会剩在另一个栈无法消去,不符合 的定义。
读者不妨可以模拟一下上图的具体过程。
前提
首先得保证存在这么一个 ,也就是存在 使得 ,即 。
其次要保证 与前面的 无关。
也就是 最后面的满足 的 不在 中,即 (也可 )。
转移
放入 一定是合法的。所以只需判 和 的合法性即可。
这时 数组不需记录信息,具体见「查找每个数放入的栈」。
if (lx[l][r] <= r) // 第一种情况 { now = lx[l][r]; if (ry < now) g[l][r] = f[l][now - 1] & f[now + 1][r]; } -
第二种:
概念

如上图,我们选择最前面的满足 的 即 ,然后把这个序列分成 、 和 三段。
对于 这段,把它们放进同一个栈(左边)。
对于 ,把它放进另一个栈(右边),它不会产生任何消除。
对于 ,把它们放进另一个栈(右边),这时它们会把 这部分剩下的全部消掉。
这样我们就不会在同一个栈(左边)剩东西,从而实现了 的转移。
为什么 一定是最后消除的呢?理由同第一种情况。
读者不妨可以模拟一下上图的具体过程。
前提
首先得保证存在这么一个 ,也就是存在 使得 ,即 。
其次必须满足两个条件之一:
-
与前面的 无关,即 (也可 );
-
不存在 ()满足 , 也就是不存在 ()满足 ,即 (也可 )。
这里简要说明一下第二个条件。
如果存在 满足 ,根据性质, 在同一个栈中且 在 上面,这样 就无法和 消去( 被 卡住了)。
总而言之就是要满足 的「有用的数」都在同一个栈的最顶部。
而区间 本身就满足「有用的数」在同一个栈的最顶部,所以可能造成干扰的是 这一部分,而不用考虑后面的部分。
转移
放入 一定是合法的。所以只需判 和 的合法性即可。
这时 数组不需记录信息,具体见「查找每个数放入的栈」。
if (lx[l][r] <= r) // 第二种情况 { now = lx[l][r]; if (xl[now] == l || r < ly[now]) { f[l][r] = g[l][now - 1] & f[now + 1][r]; } } -
-
第三种:
概念

如上图,这种情况当前区间不会产生剩余。于是我们选择 的 。
然后把区间分成 、、、 和 五段。
对于 这段,把它们放入另一个栈(右边)。
对于 ,把它放入同一个栈(左边),这时它不会产生任何消除。
对于 这段,把它们放入另一个栈(这时是左边),这时它们会把 这部分剩下的全部消掉。
为什么这时候另一个栈是左边呢?因为左边的栈已经被 堵住了,相当于是空栈(没用),但右边的栈很可能是「有用的栈」。
对于 ,把它放入另一个栈(右边),它已经和 配好对,等待 上面的数被消除即可。
对于 这段,把它们全部消掉,这时它们会把 这部分剩下的全部消掉。
最后消掉 和 。这样我们就不会剩东西,从而实现了 的转移。
很显然, 和 是最后消去的。
读者不妨可以模拟一下上图的具体过程。
前提
首先要保证没有剩余,即 。
然后枚举 的时候,要保证 与前面的 无关(否则就会被 堵住),即 (也可 )。
还有要保证 与 无关(否则就会被 堵住),即 (也可 )。
转移
放入 和消除 一定是合法的。
所以只需判 、 和 的合法性即可。
这时 数组需要记录 ,具体见「查找每个数放入的栈」。
if (lx[l][r] > r) // 第三种情况 { for (int i = l, yr = l; i <= r; i ++) { if (p[i] < yr) continue; if (ry < i) { tmp = f[l][i - 1] & f[i + 1][p[i] - 1] & both[p[i] + 1][r]; if (both[l][r] = tmp) {pboth[l][r] = i; goto skip;} } yr = p[i]; } skip:; } -
第四种:
概念

如上图,这种情况当前区间不会产生剩余。于是我们选择 的 。
然后把区间分成 、、、 和 五段。
对于 这段,把它们放入同一个栈(左边)。
对于 ,把它放入另一个栈(右边),这时它不会产生任何消除。
对于 这段,把它们放入另一个栈(右边),这时它们会把 这部分剩下的全部消掉。
对于 ,把它放入同一个栈(左边),它已经和 配好对,等待 上面的数被消除即可。
对于 这段,把它们全部消掉,这时它们会把 这部分剩下的全部消掉。
最后消掉 和 。这样我们就不会剩东西,从而实现了 的转移。
很显然, 和 是最后消去的。
读者不妨可以模拟一下上图的具体过程。
前提
首先要保证没有剩余,即 。
其次枚举 的时候,类似第二种情况,必须满足两个条件之一:
-
与前面的 无关,即 (也可 );
-
不存在 ()满足 , 也就是不存在 ()满足 ,即 (也可 )。
理由同第二种情况。
然后要保证 与前面的 无关(否则就会被 堵住),即 (也可 )。
还有要保证 与 无关(否则就会被 堵住),即 (也可 )。
转移
放入 和消除 一定是合法的。
所以只需判 、 和 的合法性即可。
这时 数组需要记录 ,具体见「查找每个数放入的栈」。
if (lx[l][r] > r) // 第四种情况 { for (int i = l, yr = l; i <= r; i ++) { if (p[i] < yr) continue; if ((xl[i] == l || r < ly[i]) && ry < p[i]) { tmp = g[l][i - 1] & f[i + 1][p[i] - 1] & both[p[i] + 1][r]; if (both[l][r] = tmp) {pboth[l][r] = p[i]; goto skip;} } yr = p[i]; } skip:; } -
-
第五种:
概念

如上图,我们选择 最小的 即 ,然后把这个序列分成 、 和 三段。
对于 这段,把它们放进同一个栈(左边)。
对于 ,把它放进另一个栈(右边),这时它不会产生任何消除。
对于 ,把它们全部消去,这时它们会把 这部分剩下的全部消掉。
这样我们就不会剩东西,从而实现了 的转移。
很显然, 是最后消去的。那为什么一定是 呢?
因为根据性质 的 肯定比它先消去(否则就堵住了),对于 的 肯定存在一种方式让 先消去。
当然也可以不选择那种方式,但是这段区间就可以拆成两个 的区间相加了。
读者不妨可以模拟一下上图的具体过程。
前提
首先要保证没有剩余,即 。
其次要保证要存在这个 ,也就是存在 的 ,即 (其实也可以判 ,上文的 同样可以换成判 )。
然后类似第二种情况,必须满足两个条件之一:
-
与前面的 无关,即 ;
-
不存在 ()满足 , 也就是不存在 ()满足 ,即 。
理由同第二种情况。
转移
放入 一定是合法的。所以只需判 和 的合法性即可。
这时 数组需要记录 ,具体见「查找每个数放入的栈」。
if (lx[l][r] > r) // 第五种情况 { if (xl[r] < l) { now = p[xl[r]]; if (xl[now - 1] == l || r < ly[now - 1]) { tmp = g[l][now - 1] & both[now + 1][r]; if (both[l][r] = tmp) pboth[l][r] = -now; } } } -
容易发现只有这几种情况,分别转移即可。对于第二、四、五种情况,其实如果预处理 ,那么前提两个条件中的第一个条件可以略去。
因为当 时, 一定等于无穷大,也就是满足 。
只是作者太懒了代码不想改 qwq。目标状态
如果 ,则有解(输出
Cleared.);否则无解(输出No solution)。关于 数组的补充说明
很显然,当 内没有剩余即 时, 数组取 和 任意一个都行(相当于把空集堆在任意一个栈)。
因此我们转移时可以把 都换成 ,转移后再把 就可以了。
记录上一个状态的数组 也可换成 ,转移后再把 即可。
关于性质的粗略证明
证明:
考虑用数学归纳法。命题对于 显然成立(都没有「有用的数」)。
设命题对于 成立,接下来证明命题对于由它分割的一个子区间 依然成立。
对于第一种情况(), 的「有用的数」都是 的,命题对于 显然成立;
而前提保证 的「有用的数」都在 中被堆在了另一个栈且只剩下「有用的数」,命题也成立。
对于第二种情况(),根据我们在第二种情况时的讨论,命题对于 显然成立;
而 的「有用的数」要么就在之前「有用的栈」的最顶部,要么就在 剩下的当中,命题也成立。
因为前提保证了 只会剩下「有用的数」,所以「有用的数」仍在同一个栈的最顶部。
对于第三种情况(),同第一种情况,命题对于 显然成立;
命题对于 同样成立,理由同第一种情况;
前提保证了 和 部分都没有 的「有用的数」,所以「有用的数」只会在 当中,命题也成立。
因为前提保证了 只会剩下「有用的数」,所以「有用的数」仍在同一个栈的最顶部。
对于第四种情况(),同第二种情况,命题对于 显然成立;
命题对于 同样成立,理由同第二种情况;
对于 这部分同第三种情况,命题也成立。
对于第五种情况(),同第二种情况,命题对于 显然成立;
命题对于 同样成立,理由同第二种情况。
证毕。
Part 3:求具体方案
首先容易发现 ,因为每个数都被进行了一次加入操作,两个数一组被进行了一次消除操作。
查找每个数放入的栈
设 为第 个数应该放入的栈。 表示放入栈 , 表示放入栈 。
记 $pre _ {l, r, w} = \begin {cases} pf _ {l, r} & (w = 1) \\ pg _ {l, r} & (w = 0) \end {cases}$,可以有效简化步骤。
特别提醒:根据「关于 数组的补充说明」,此时 数组已并入 和 中, 数组已并入 和 中。
考虑递归查找。需要传入四个参数:,表示当前递归到区间 ,是第 种转移方式,同一个栈为栈 。
这里 表示转移方式 , 表示转移方式 ; 表示栈 , 表示栈 。
查找的入口为区间 ,我们钦定 。
如果当前递归查找的区间为 ,是第 种转移方式,同一个栈为栈 ,分几种情况:
-
第一、二种情况
判定
如果满足 ,那么说明是第一、二种情况。
查找分界点放入的栈
不管是第一种情况还是第二种情况,分界点都是 。
然而还要考虑 的影响。发现 的分界点被放入另一个栈,而 的分界点被放入同一个栈。也就是说 时要反过来。
总结规律可以得出 。
递归
第一种情况是 ,第二种情况是 。
发现两种情况的共同点是都只有两个子区间,其中左边子区间的转移方式与当前区间相反,且右边子区间转移方式为 。
而左边子区间同一个栈与当前区间相同,右边子区间同一个栈如果 那么还要反过来。
所以分别递归 和 。
-
第三种情况
判定
如果满足 且 且 ,那么说明是第三种情况。
查找分界点放入的栈
靠左的分界点 会被放入同一个栈,靠右的分界点 会被放入另一个栈。
令 ,。
递归
三个子区间转移方式都为 (这里我们把右边子区间的转移方式钦定为 )。
左边子区间同一个栈与当前区间相同,中间子区间同一个栈与当前区间相反,右边子区间同一个栈与当前区间相同。
所以分别递归 、$(pre _ {l, r, w} + 1, p _ {pre _ {l, r, w}} - 1, 1, !d)$ 和 。
-
第四种情况
判定
如果满足 且 且 ,那么说明是第四种情况。
查找分界点放入的栈
靠左的分界点 会被放入另一个栈,靠右的分界点 会被放入同一个栈。
令 ,。
递归
左边子区间转移方式为 ,其它子区间转移方式都为 (这里我们把右边子区间的转移方式钦定为 )。
左边子区间同一个栈与当前区间相同,中间子区间同一个栈与当前区间相同,右边子区间同一个栈与当前区间相反。
所以分别递归 、$(p _ {pre _ {l, r, w}} + 1, p _ {l, r, w} - 1, 1, d)$ 和 。
-
第五种情况
判定
如果满足 且 ,那么说明是第五种情况。
查找分界点放入的栈
分界点 会被放入另一个栈。
令 。
递归
左边子区间转移方式为 ,右边子区间转移方式我们钦定为 。
左边子区间和右边子区间同一个栈都与当前区间相同。
所以分别递归 和 。
模拟具体操作
得出 数组后,我们从前往后遍历每一个数。设当前遍历到位置 ,数为 。
首先如果 ,那么输出
1;否则输出2。然后把 压入对应的栈中。在栈顶数字相同的情况下,一直输出
0并弹出两边栈顶。
于是我们就可以
愉快地搞定一道黑题啦。下面附上 AC 代码:AC Code
#include <cstdio> #include <cstring> #define inf 0x3f3f3f3f #define N 1505 #define min(x,y) ((x)<(y)?(x):(y)) using namespace std; int n, a[N], l[N], p[N], gt[N], pf[N][N], pg[N][N]; int lx[N][N], xl[N], ly[N], tr[N]; int top[2], st[2][N]; // 数组模拟栈 bool tmp, f[N][N], g[N][N]; int &pre (int i, int j, bool k) // 合并两个数组为一个函数 { return k ? pf[i][j] : pg[i][j]; } // 这里的树状数组写法有些不同,实现的是单点修改,区间(后缀)询问 void modify (int p, int c) // 树状数组加入元素 { for (; p; p &= p - 1) tr[p] = min (tr[p], c); return ; } int ask (int p) // 树状数组询问 { int res = inf; for (; p <= n; p += p & -p) res = min (res, tr[p]); return res; } void dfs (int l, int r, bool w, bool d) // dfs 求具体方案 { if (l > r) return ; if (lx[l][r] <= r) { gt[lx[l][r]] = w ^ d; dfs (l, lx[l][r] - 1, !w, d); dfs (lx[l][r] + 1, r, 1, !w ^ d); } else { if (pre (l, r, w) > 0) { gt[pre (l, r, w)] = d; gt[p[pre (l, r, w)]] = !d; if (pre (l, r, w) < p[pre (l, r, w)]) { dfs (l, pre (l, r, w) - 1, 1, d); dfs (pre (l, r, w) + 1, p[pre (l, r, w)] - 1, 1, !d); dfs (p[pre (l, r, w)] + 1, r, 1, d); } else { dfs (l, p[pre (l, r, w)] - 1, 0, d); dfs (p[pre (l, r, w)] + 1, pre (l, r, w) - 1, 1, d); dfs (pre (l, r, w) + 1, r, 1, !d); } } else { gt[-pre (l, r, w)] = !d; dfs (l, -pre (l, r, w) - 1, 0, d); dfs (-pre (l, r, w) + 1, r, 1, d); } } return ; } int main () { scanf ("%d", &n), f[1][0] = g[1][0] = 1; // 初始化 for (int i = 1; i <= n; i ++) { scanf ("%d", &a[i]); if (l[a[i]]) p[l[a[i]]] = i, p[i] = l[a[i]]; // 预处理 l[a[i]] = i, f[i + 1][i] = g[i + 1][i] = 1; // 初始化 } for (int r = 1; r <= n; r ++) { lx[r + 1][r] = r + 1; // 初始化 for (int l = r; l; l --) // 预处理 { lx[l][r] = lx[l + 1][r]; if (p[l] > r) lx[l][r] = l; } } for (int l = n, ry = 0; l; l --, ry = 0) { xl[l - 1] = l, memset (tr, 0x3f, sizeof tr); // 初始化 for (int r = l; r <= n; r ++) // 预处理 { xl[r] = min (xl[r - 1], p[r]); } for (int r = n; r >= l; r --) // 预处理 { ly[r] = ask (xl[r]); if (p[r] < l) modify (p[r], r); } for (int r = l, now; r <= n; r ++) // 区间 dp { if (p[r] < l) ry = r; // 顺便预处理 if (lx[l][r] <= r) { now = lx[l][r]; if (ry < now) g[l][r] = f[l][now - 1] & f[now + 1][r]; // 第一种情况 if (xl[now] == l || r < ly[now]) // 第二种情况 { f[l][r] = g[l][now - 1] & f[now + 1][r]; } } else { for (int i = l, yr = l; i <= r; i ++) { if (p[i] < yr) continue; if (ry < i) // 第三种情况 { tmp = f[l][i - 1] & f[i + 1][p[i] - 1] & f[p[i] + 1][r]; if (f[l][r] = tmp) {pf[l][r] = i; goto skip;} } if ((xl[i] == l || r < ly[i]) && ry < p[i]) // 第四种情况 { tmp = g[l][i - 1] & f[i + 1][p[i] - 1] & f[p[i] + 1][r]; if (f[l][r] = tmp) {pf[l][r] = p[i]; goto skip;} } yr = p[i]; // 顺便预处理 } if (xl[r] < l) { now = p[xl[r]]; if (xl[now - 1] == l || r < ly[now - 1]) // 第五种情况 { tmp = g[l][now - 1] & f[now + 1][r]; if (f[l][r] = tmp) pf[l][r] = -now; } } skip:; g[l][r] = f[l][r], pg[l][r] = pf[l][r]; // 关于 Both 的处理 } } } puts (f[1][n] ? "Cleared." : "No solution."); if (!f[1][n]) return 0; printf ("%d\n", n / 2 * 3), dfs (1, n, 0, 0); for (int i = 1; i <= n; i ++) // 模拟 { putchar ('1' + gt[i]), st[gt[i]][++ top[gt[i]]] = a[i]; while (top[0] && top[1] && st[0][top[0]] == st[1][top[1]]) { putchar ('0'), top[0] --, top[1] --; } } return 0; }题解若有问题欢迎在评论区反馈。
-
- 1