1 条题解
-
0
自动搬运
来自洛谷,原作者为

KiDDOwithTopTree
这个家伙很废,什么也没有留下搬运于
2025-08-24 22:18:05,当前版本为作者最后更新于2021-02-09 14:39:43,作者可能在搬运后再次修改,您可在原文处查看最新版自动搬运只会搬运当前题目点赞数最高的题解,您可前往洛谷题解查看更多
以下是正文
目录
-
前置芝士
-
序
-
离线构造
-
在线构造
-
代码实现
-
与其他后缀数据结构的比较
-
例题
-
参考资料
前置芝士
重量平衡树。
此重量平衡树的定义为:
在插入或删除操作之后,为了保持树的平衡而重构的子树大小为均摊或期望 。
只要是重量平衡树就可以了。主要有替罪羊树、、 等。
本文将以 为例,介绍后缀平衡树。

(图源:https://www.luogu.com.cn/blog/85514/fhq-treap-xue-xi-bi-ji)
0. 序
这一段并没有什么用,直接学算法的可以跳过。
众所周知,后缀数据结构博大精深。包括有:后缀树、后缀数组、后缀自动姬与后缀平衡树。同时背诵 种数据结构的模板也忒累了。于是我就开始想偷工减料。
首先,反串的后缀自动姬的 就是后缀树。这么一来,一个算法就可以同时构造两种数据结构。完美!
然后就剩下后缀数组了。但是这东西不讲武德。看着很简单,但是很遗憾,我看了半天也没懂基数排序,其他两种 办法也看不懂…于是我只能想其他办法…
欸,不是还有后缀平衡树吗?可不可以用后缀平衡树来解决后缀数组呢?
那就试试看咯。
1. 概念
后缀平衡树。由字面意思可得,它是一种维护后缀的数据结构。它可以维护一个字符串的所有后缀。
那如果用来维护前缀是不是就是前缀平衡树了?很显然,平衡树是可以用来排序的。那么后缀平衡树就是用来把这些后缀进行排序的。
怎么排序呢?
那当然是字典序啦。
所以这就是后缀平衡树的定义:
考虑一个长度为 的字符串 ,定义 为其由 组成的后缀。
后缀之间的大小由字典序定义,后缀平衡树就是一个平衡树并维护这些后缀的顺序。
2. 离线构造
那么我们试着来建立一棵后缀平衡树:
我们先写出字符串 的所有后缀:。
把这一些后缀按照字典序进行从小到大的排序:。
把它们像替罪羊树一样二分拎起来,不就是一棵后缀平衡树了吗?
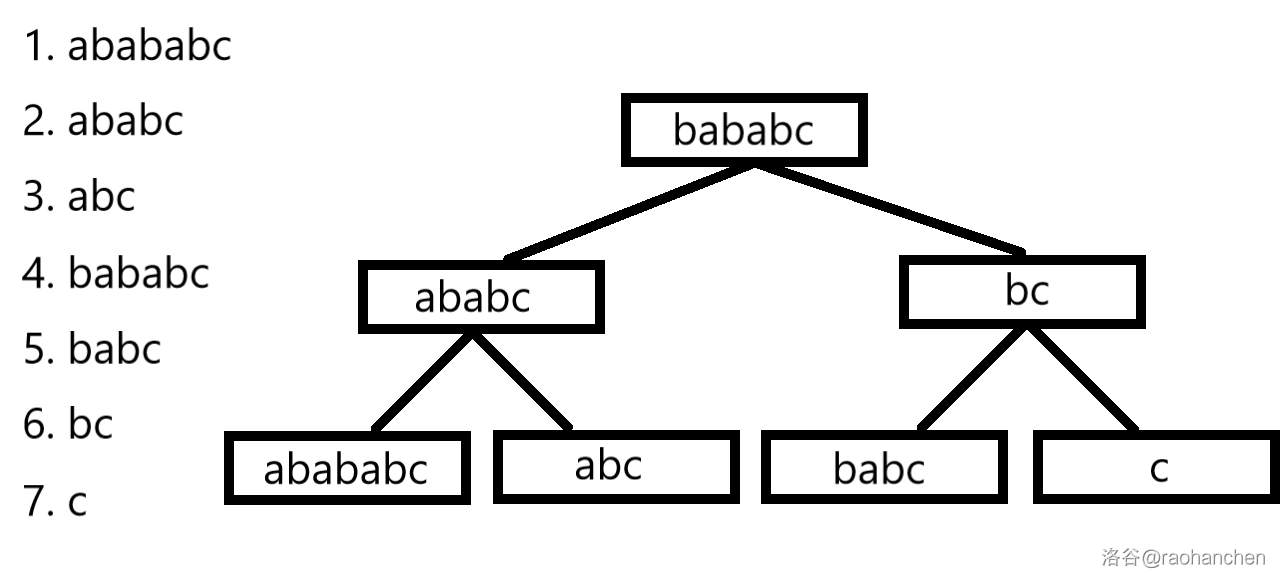 (上图是字符串 的所有后缀的排序结果与所建立的后缀平衡树)
(上图是字符串 的所有后缀的排序结果与所建立的后缀平衡树)很简单对不。
好家伙,这不还需要先求出后缀数组来吗?
时复为 或 ,取决于所用后缀数组的算法。
上面的方法为构造后缀平衡树的离线算法。
虽然这可以建出后缀数组来,但是并不能在线解决问题。
也不能解决我不会求后缀数组的问题。
3. 在线构造
那么我们如何在线构造呢?
那我们可以把这个字符串的后缀一个一个地把插入进去平衡树。
怎么插入呢?
我们遍历到每一个节点,用即将插入的后缀 和此节点代表的后缀 按照字典序比较。如果 ,那么就向左儿子插入;如果 ,那么就向右儿子插入。因为每一个后缀的长度都不一样,所以没有相同的情况。
我们以字符串 为例,把 的所有后缀插入一棵平衡树:(平衡树以 为例,黑字为节点代表的字符串,蓝字为节点的 值(随机权值))
1. 插入后缀 :
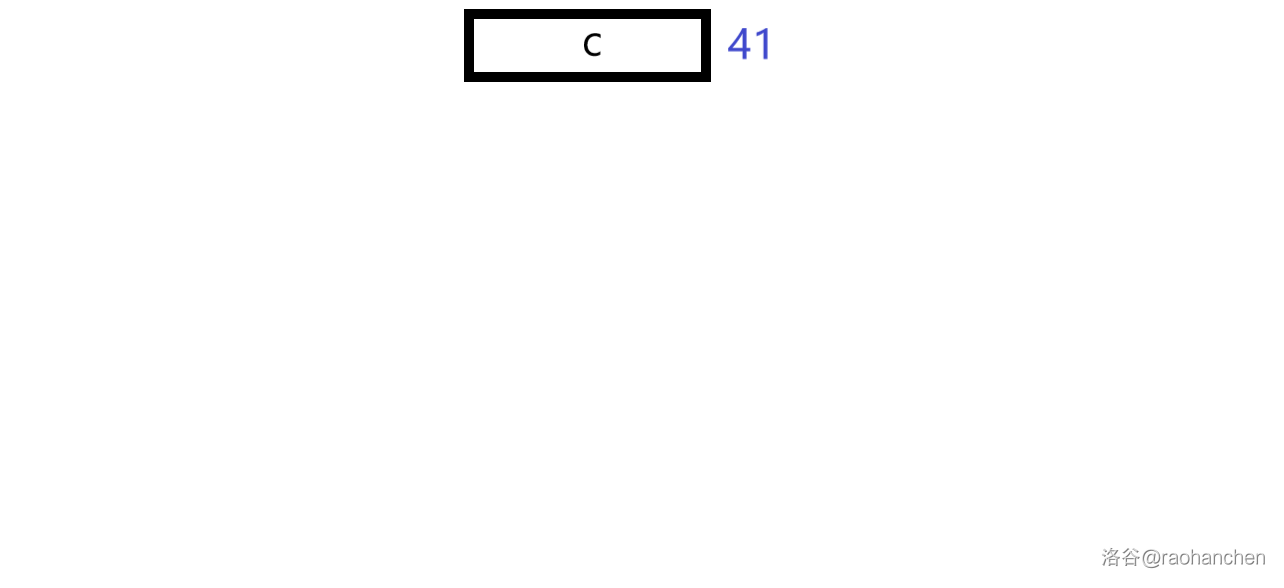
2. 插入后缀 :
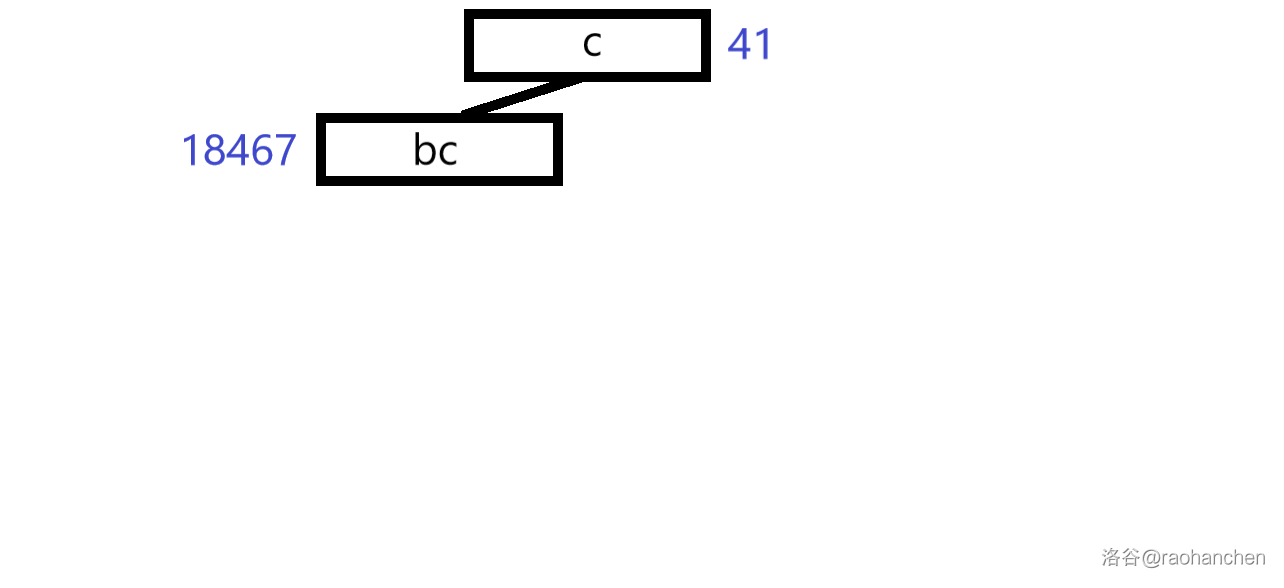
3. 插入后缀 :

不满足堆性质,进行旋转调整:
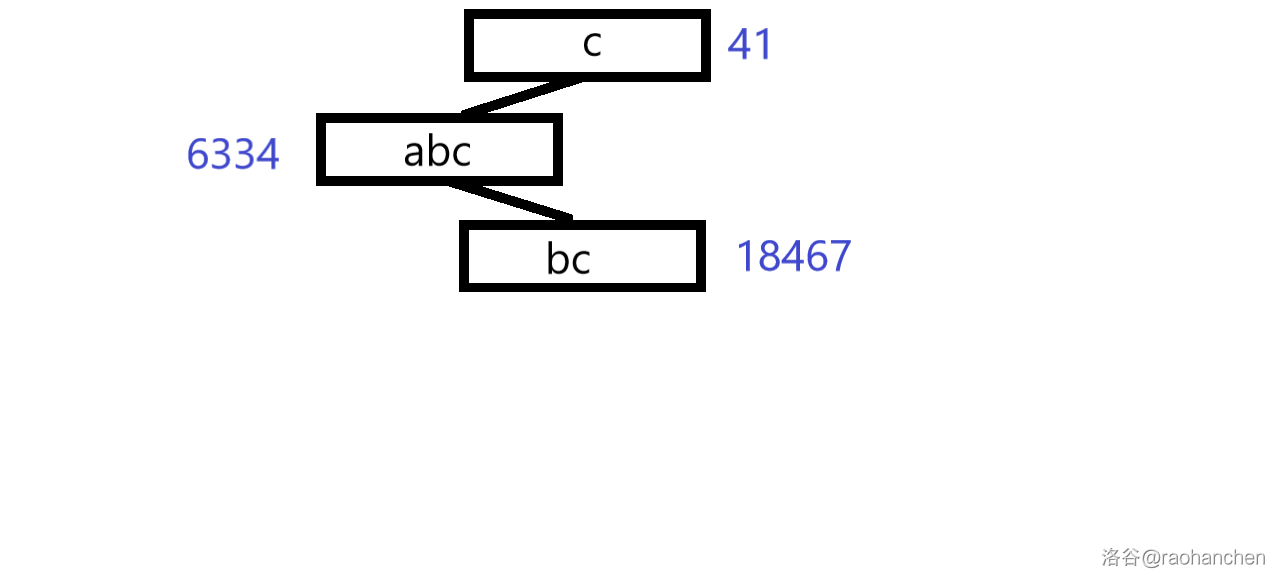
4. 插入后缀 :
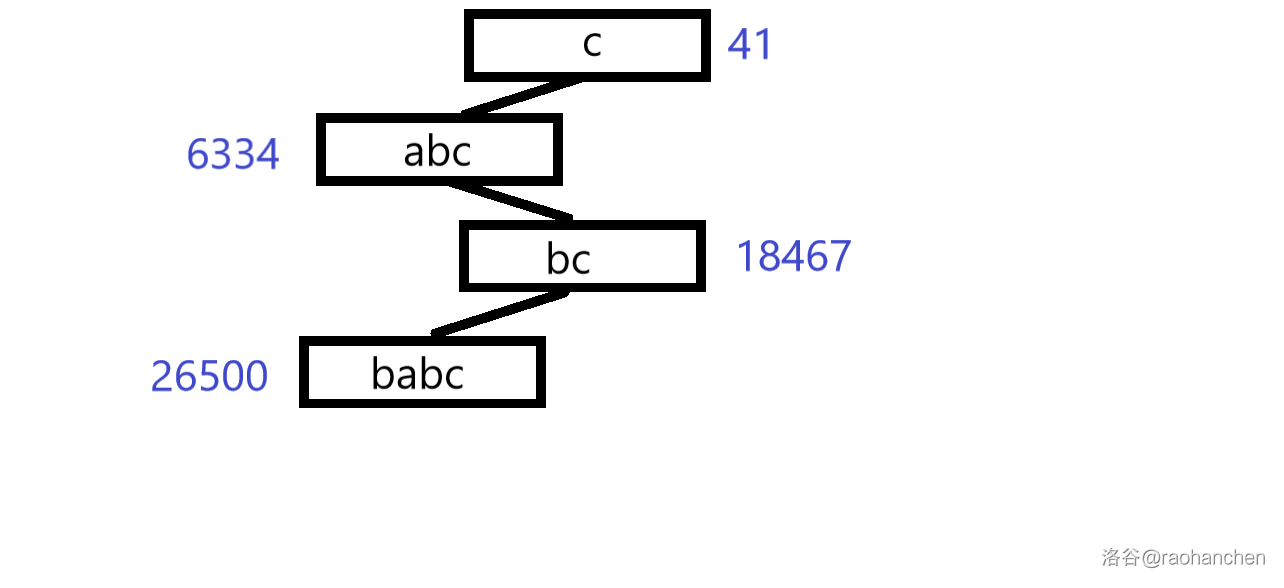
5. 插入后缀 :
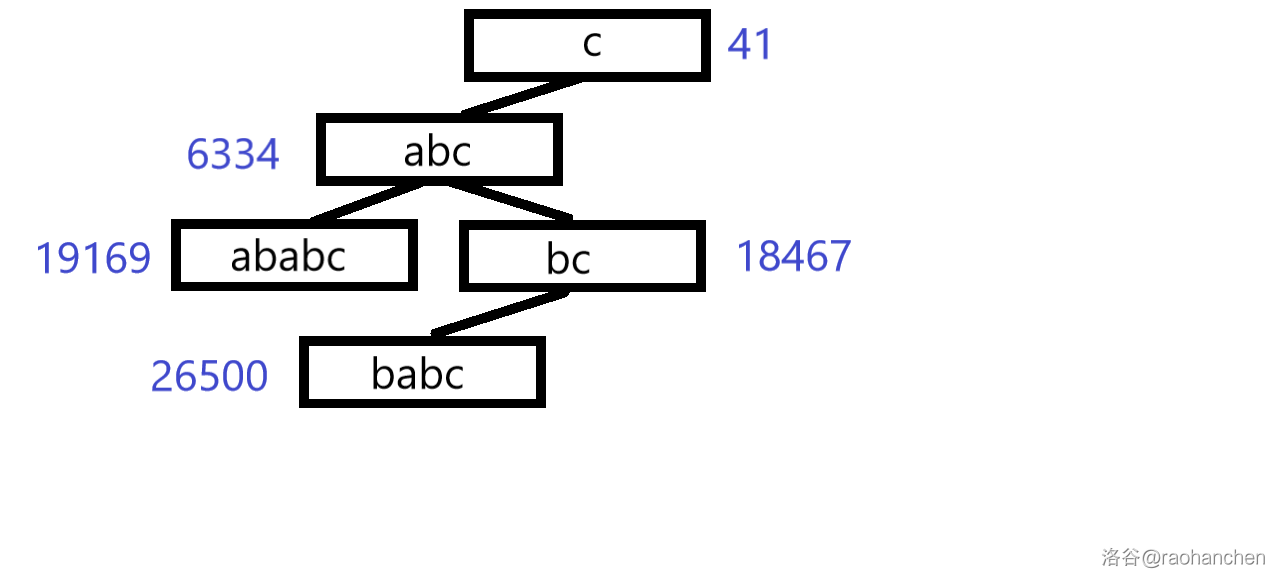
6. 插入后缀 :

不满足堆性质,进行旋转调整:
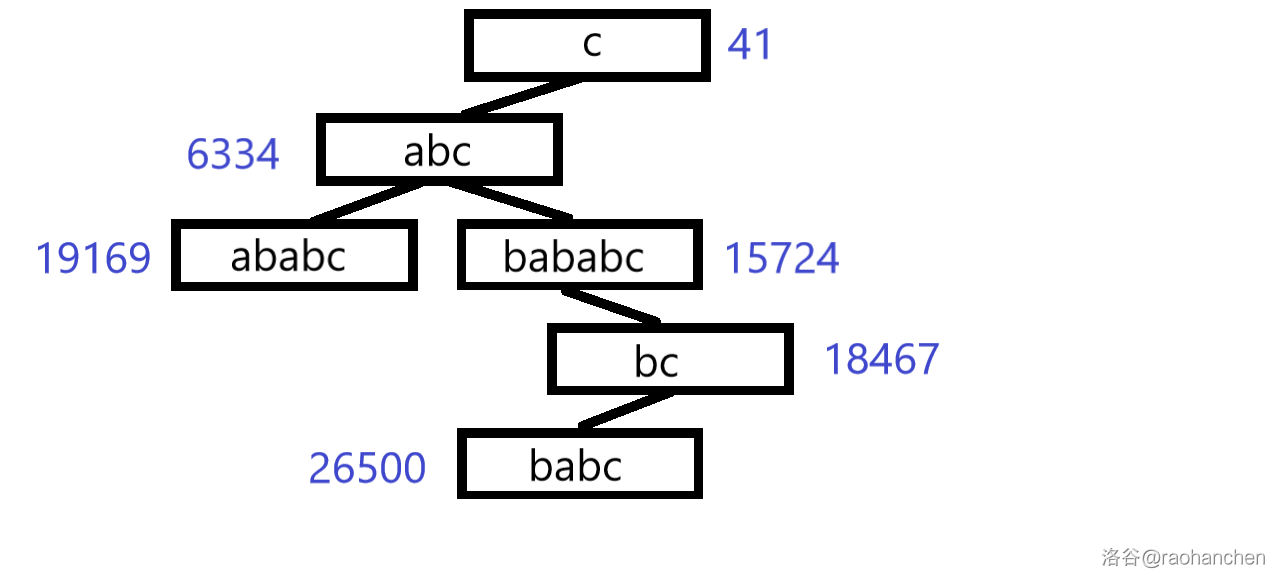
7. 插入后缀 :
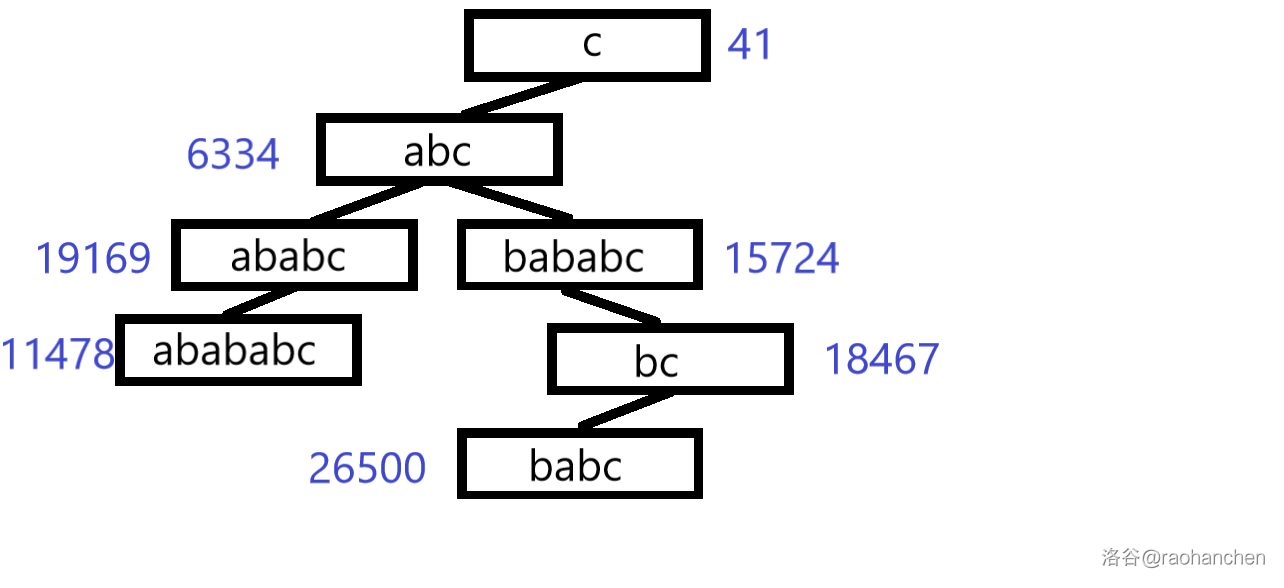
不满足堆性质,进行旋转调整:
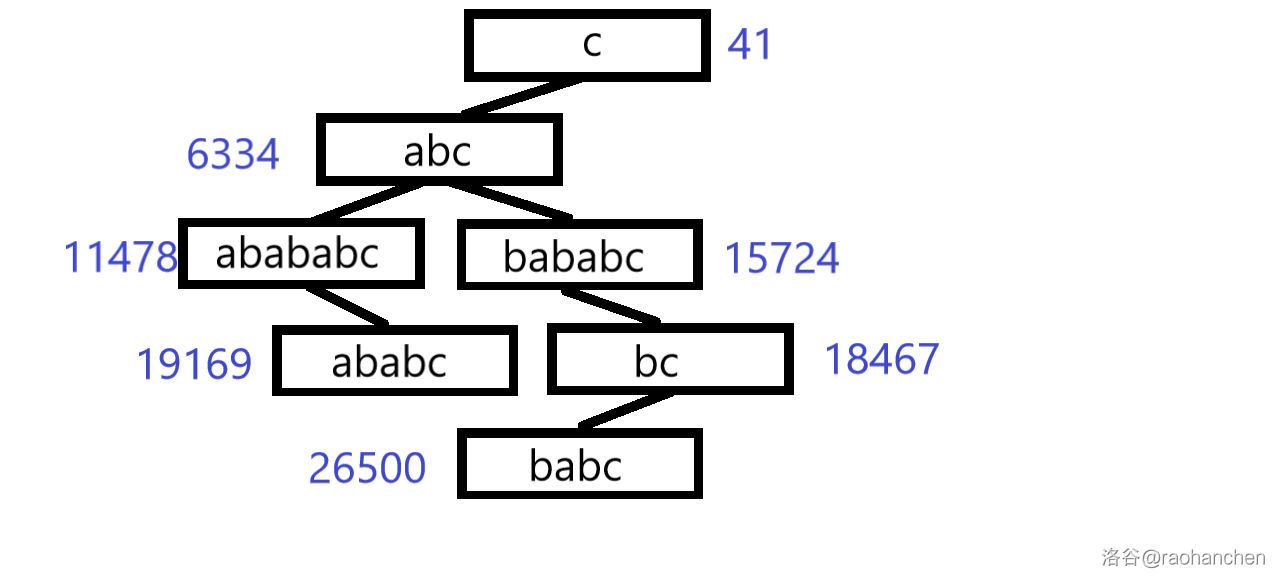
至此,关于字符串 所有后缀的后缀平衡树已经建立完成了。
我们发现,建立一棵后缀平衡树,其实是把后缀一个一个地插入进平衡树中。
既然有插入一个后缀的操作,那么也应该有删除一个后缀的操作。
我们对于刚才建立的这一棵平衡树,我们把这些后缀一个一个删除。
0. 原图:
1. 删除后缀 :
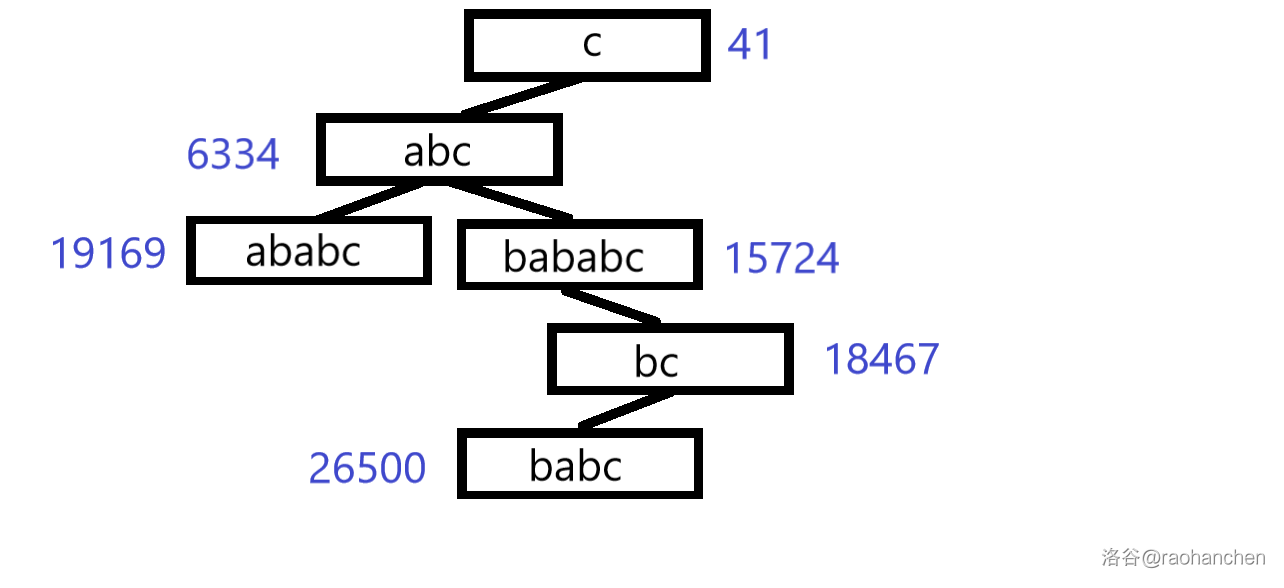
2. 删除后缀 :
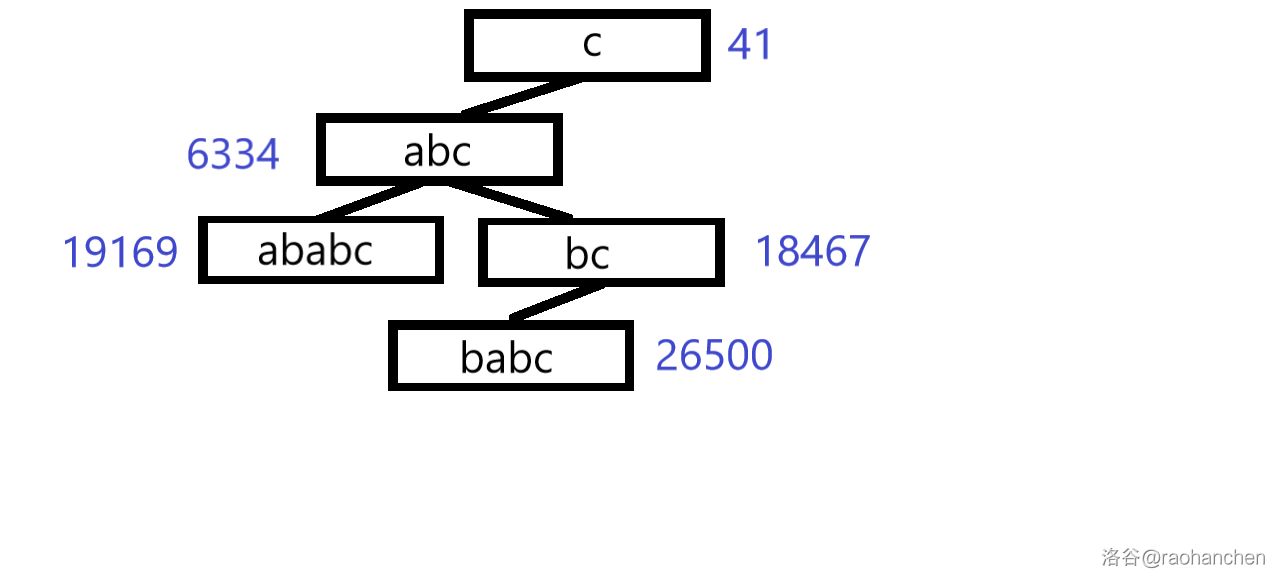
3. 删除后缀 :
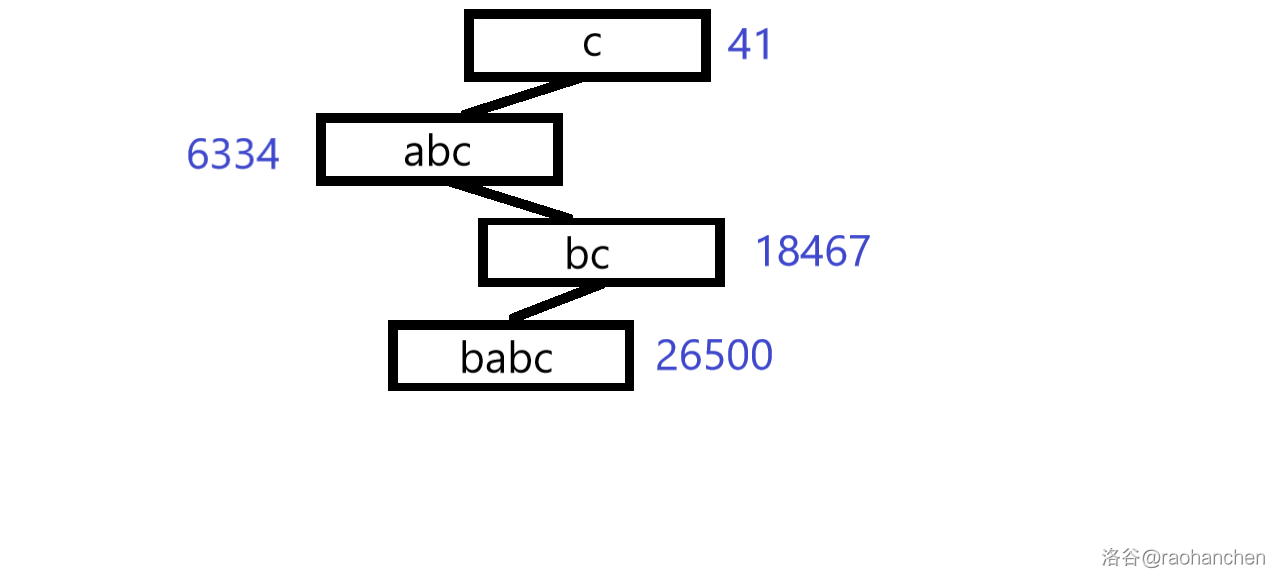
4. 删除后缀 :
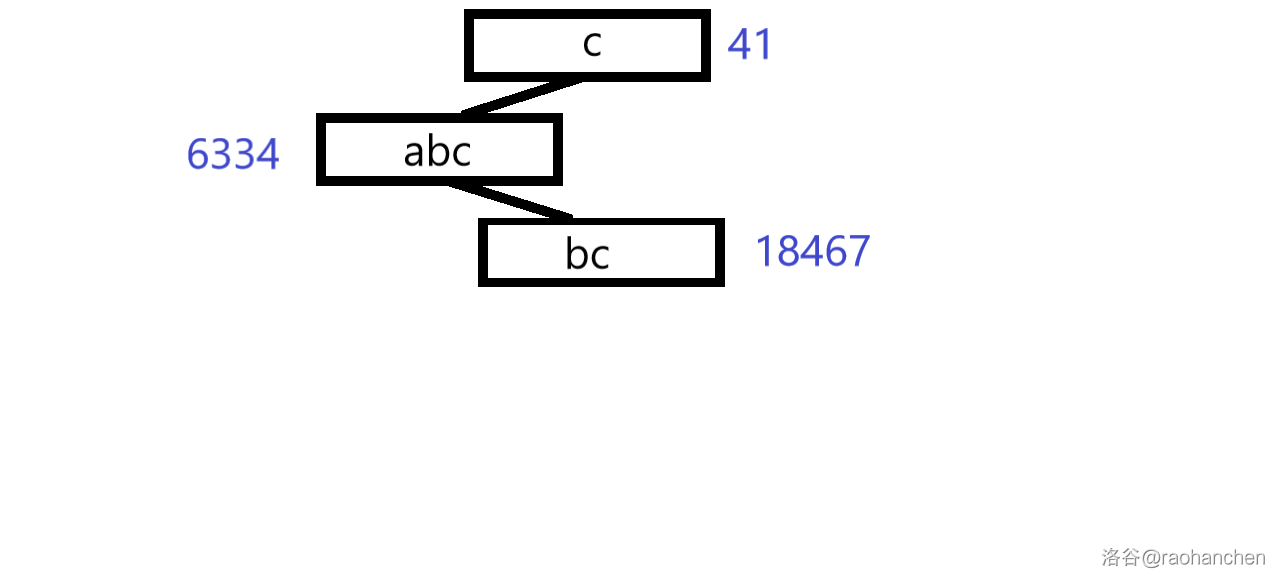
5. 删除后缀 :
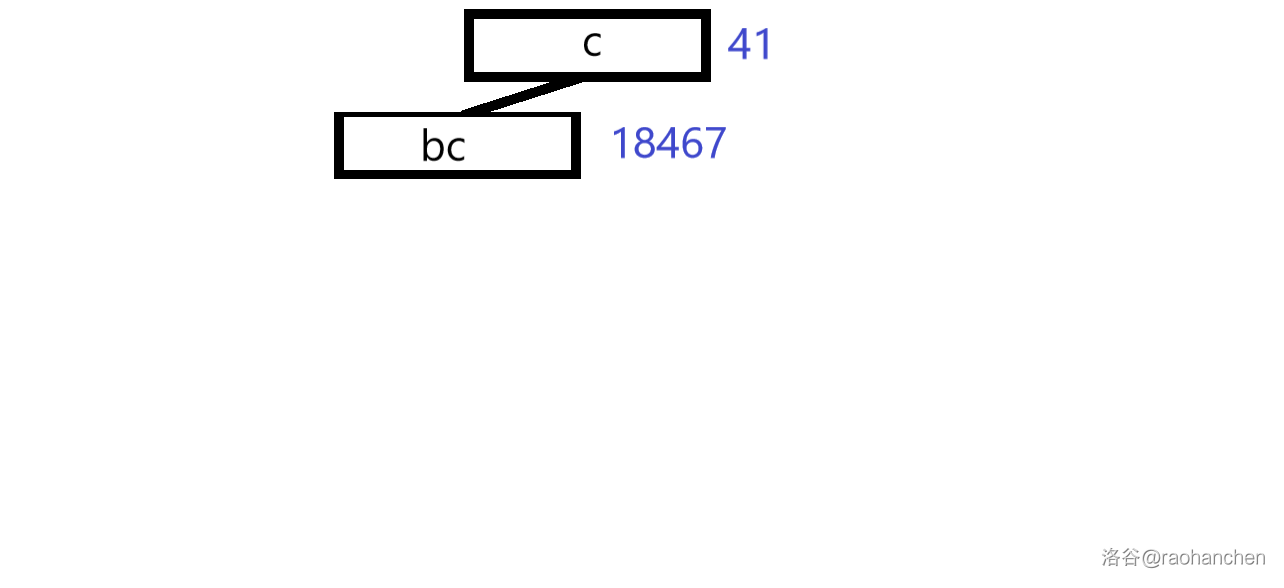
6. 删除后缀 :
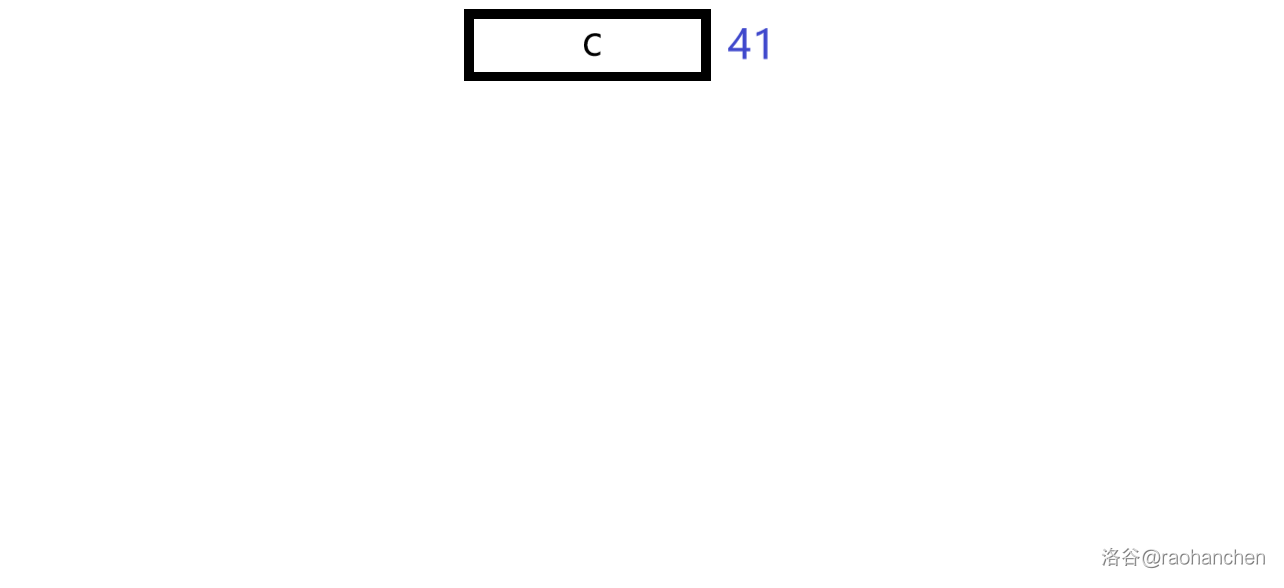
7. 删除后缀 :
删空了,就不放图片了。
这个例子貌似不太好…那就再来一个例子吧。
其实是来凑字数的。0. 原图:
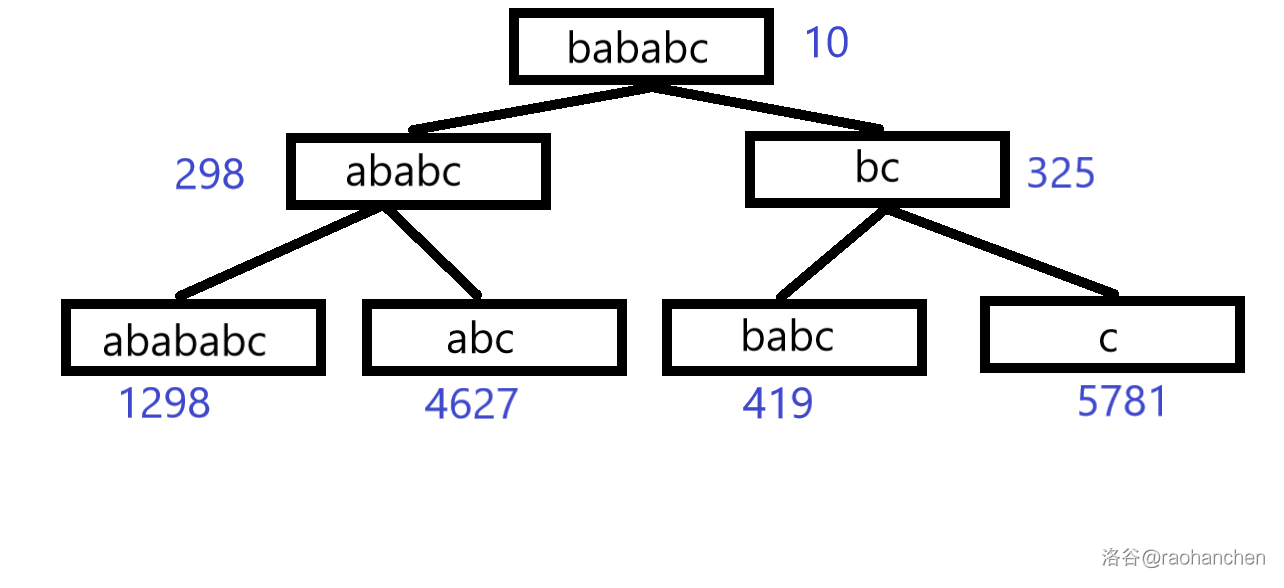
1. 删除后缀 :
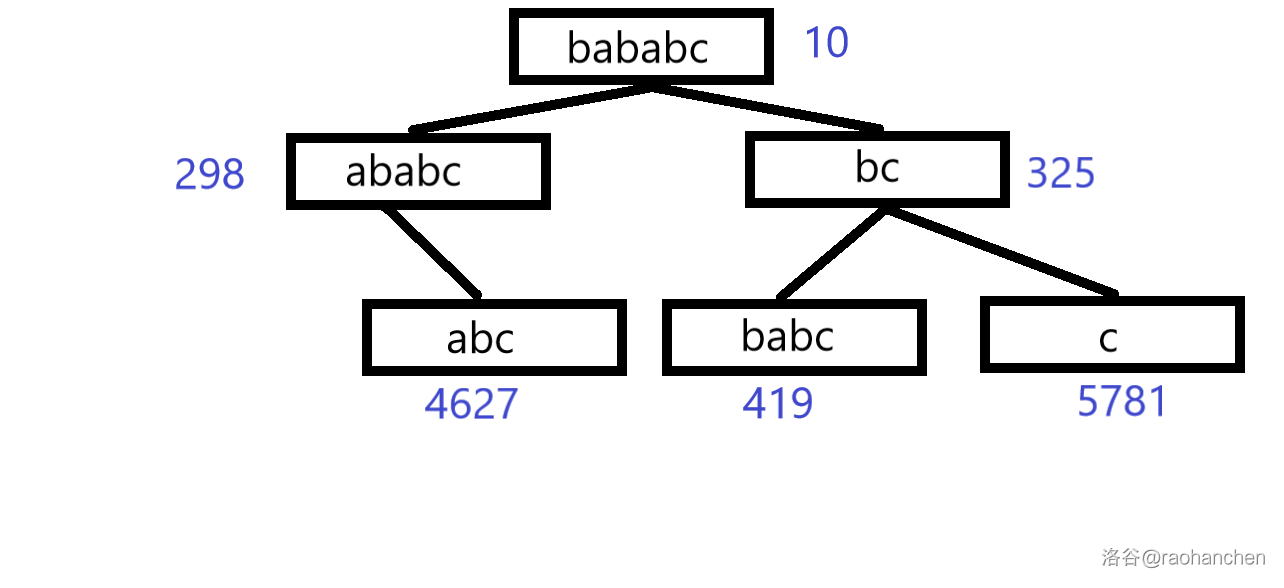
2. 删除后缀 :
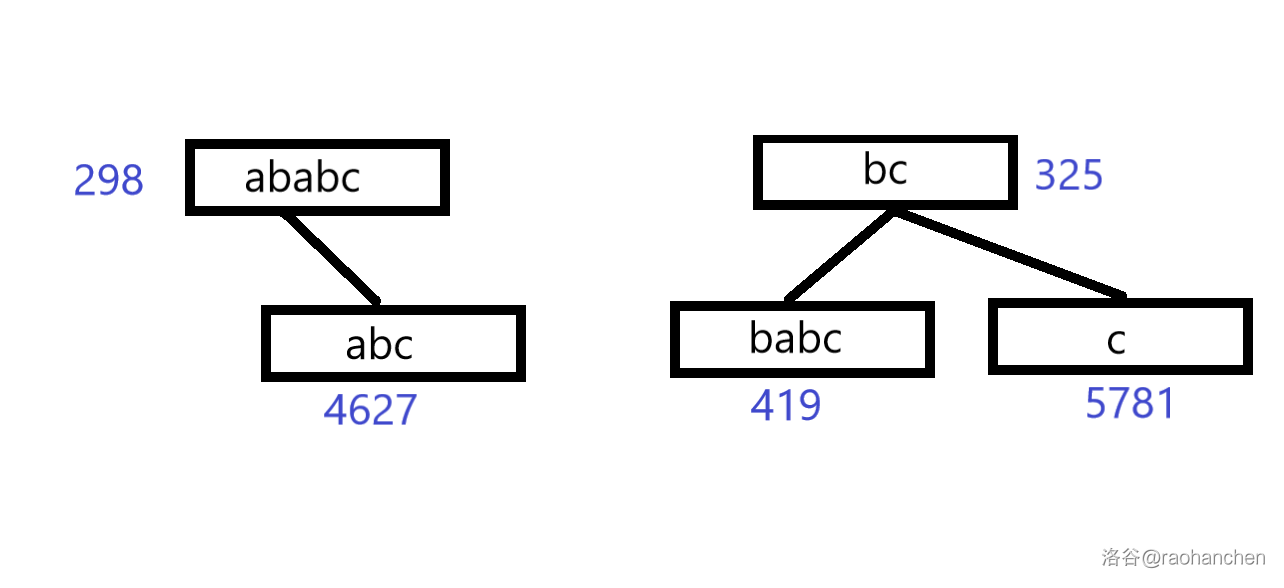
如图,左右子树分成了两部分,为了避免分类讨论,我把它用 的 操作进行合并(当然也可以直接写 的分类讨论):
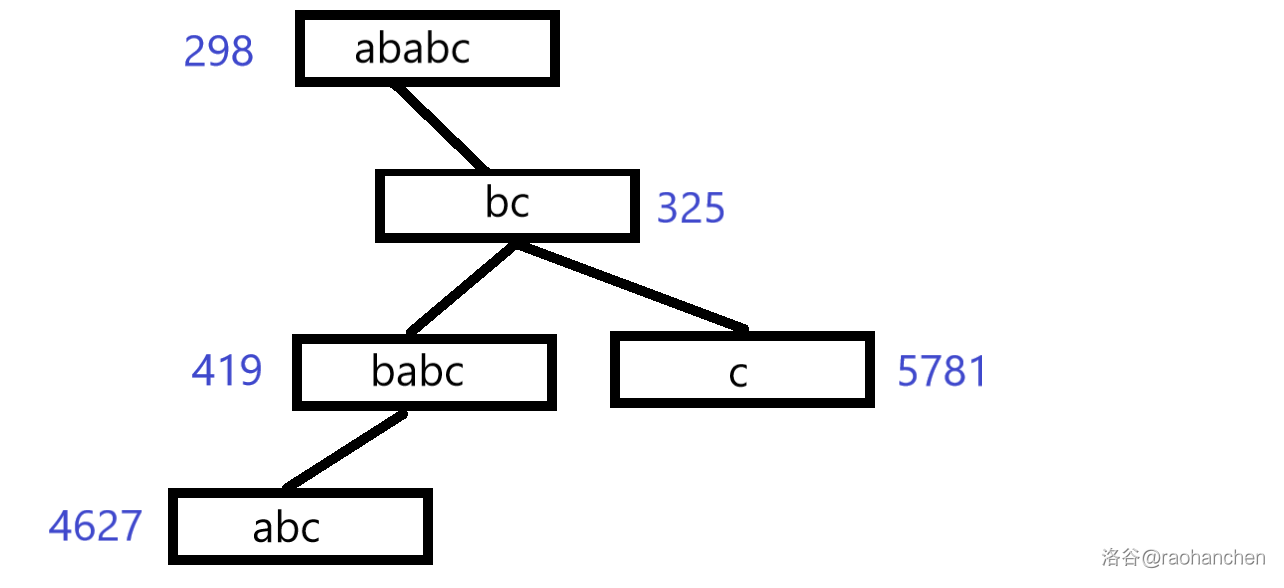
3. 删除后缀 :
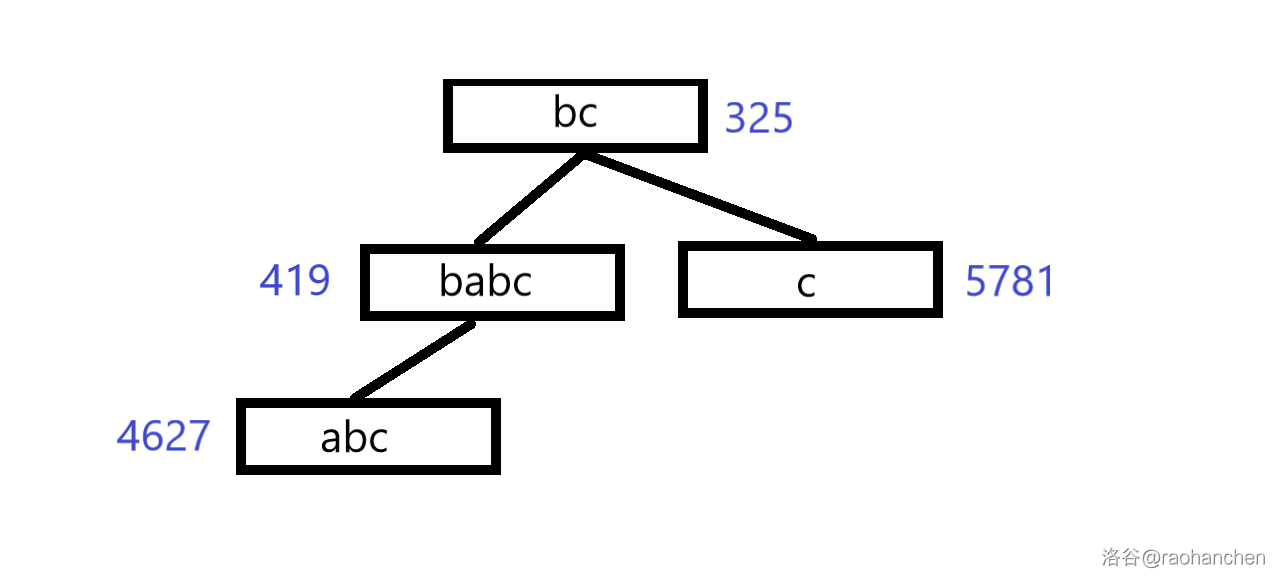
4. 删除后缀 :
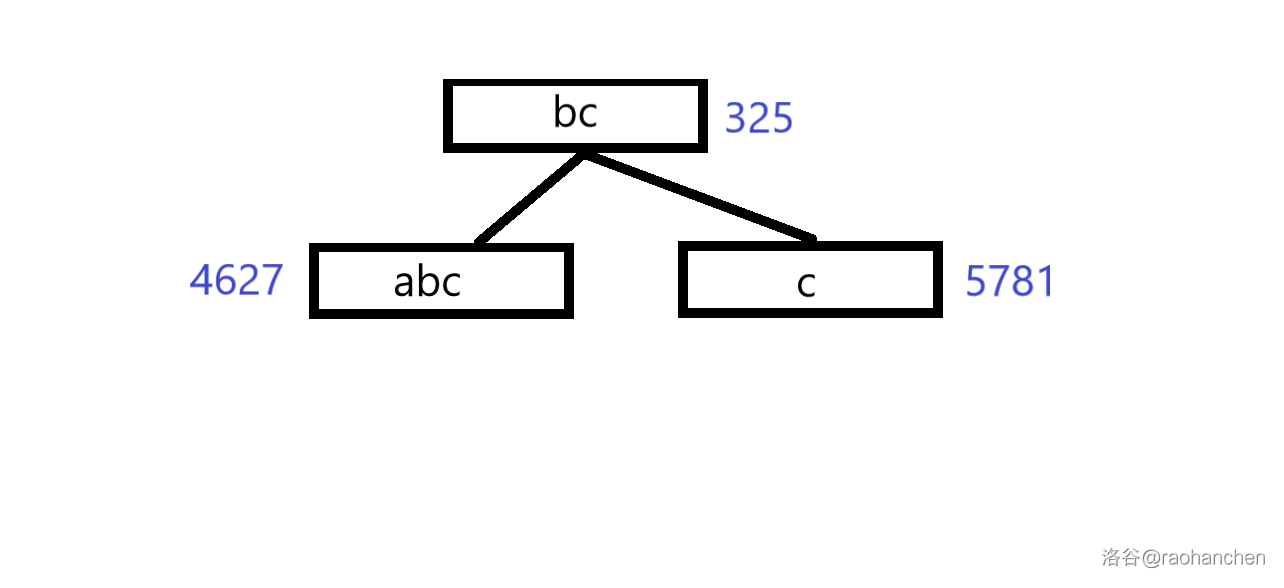
5. 删除后缀 :
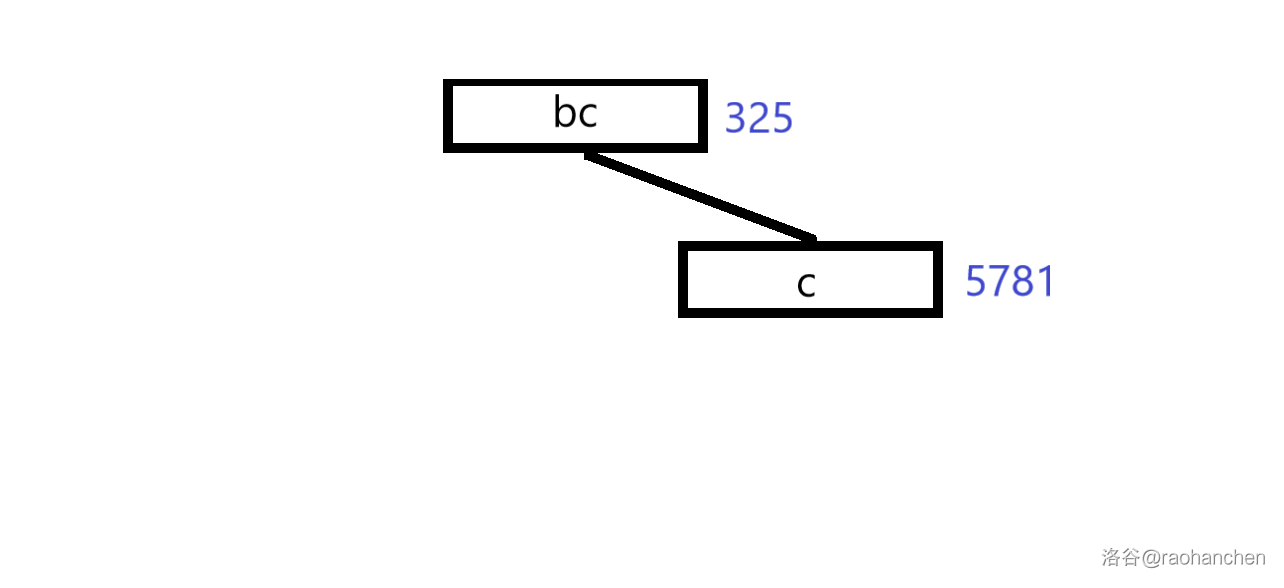
6. 删除后缀 :
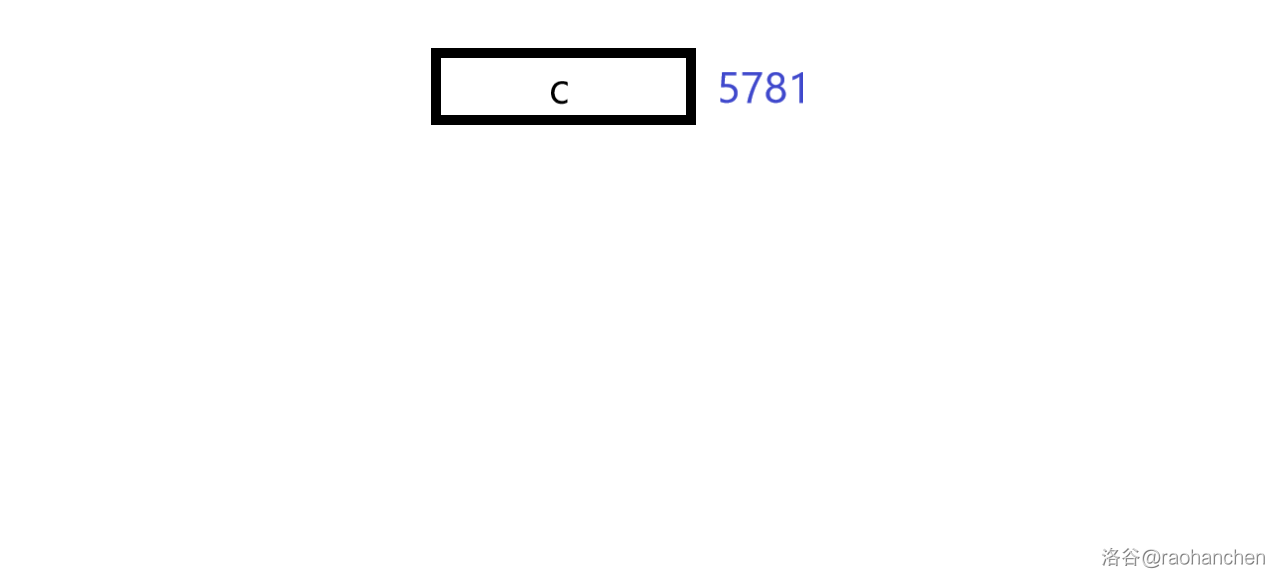
7. 删除后缀 :
删空了,就不放图片了。
我们可以发现,后缀平衡树可以资瓷动态插入一个后缀和删除一个后缀。
毕竟是插入和删除一个后缀,所以后缀平衡树是资瓷在一个字符串前插入或删除一个字符。
这一点与后缀自动姬不同。后缀自动姬是在后面插入一个字符,而后缀平衡树是在前面插入一个字符。两者要注意区分。
为什么是在前面呢?
因为如果是在后面插入一个字符的话,那么原有的那些后缀的关系就全部打乱了。设原来字符串的长度为 ,那么我们就要把原来的 个后缀全部删除,再插入新的 个后缀。删除一个字符同理。如果在前面插入一个字符的话,假设原有字符串为 ,新插入的字符为 ,那么原有的后缀其实并没有改变,其实只是新插入了一个后缀 。删除也是同理。
可以发现,其实后缀平衡树并不难,容易理解。在比赛上是个不错的选择。
4. 代码实现
思路都很好理解,那代码呢?
其实也不难。
我们先把普通平衡树的插入给放上来:
void ins(int &now,int val){ if(!now){ now=++tot; tr[now].size=tr[now].cnt=1; tr[now].val=val; tr[now].key=rand(); return ; } if(tr[now].val==val){ tr[now].cnt++; pushup(now); } else if(tr[now].val>val){ ins(tr[now].lson,val); pushup(now); if(tr[now].key<tr[tr[now].lson].key) zig(now); } else{ ins(tr[now].rson,val); pushup(now); if(tr[now].key<tr[tr[now].rson].key) zag(now); } }我们把它魔改成后缀平衡树…
欸, 是什么,后缀没有赋权值啊。
那又怎么样?我们可以直接把要插入的后缀与节点所代表的后缀进行比较不就行啦?
那不可能一个节点上就放一个字符串啊。这还不会爆空间?
那么我们就应该想其他的方法。
我们可以把一个节点的编号设为后缀开始的的位置。例如节点 就代表从 开始的后缀。那么我们就可以这样写:
void ins(int &now,int pos){//now为现在访问到的编号,pos为插入后缀的开始节点 if(!now){//新建节点 trp[pos].key=rand(); trp[pos].size=1; trp[pos].cnt=1; now=pos;//节点编号为后缀开始的位置 return ; } if(comp(now,pos)>0){//比较,如果大于0则now代表的后缀的字典序大于pos代表的后缀的字典序 ins(trp[now].lson,pos); pushup(now); if(trp[now].key>trp[trp[now].lson].key) zig(now); } else if(comp(now,pos)<0){//小于0则now代表的后缀的字典序小于pos代表的后缀的字典序 ins(trp[now].rson,pos); pushup(now); if(trp[now].key>trp[trp[now].rson].key) zag(now); } else{//等于0,字典序相等,后缀相同(其实不可能出现这种情况) trp[now].cnt++; pushup(now); } }
不错。那么后缀平衡树的插入操作就解决啦。还有一个问题呢: 函数怎么写?
1. 暴力比较:
最简单的一种方法:直接暴力遍历两个字符串,对其进行比较:
inline int comp(int x,int y){ for(int i=x,j=y;s[i]||s[j];i++,j++) if(s[i]>s[j]) return 1; else if(s[i]<s[j]) return -1; return 0; }一次比较就需要 的时复。一次插入就要 的时复。直接原地升天。
2. + 二分:
这个方法需要二分找出两个后缀的最长公共前缀()。因为公共前缀的部分一定一样,那么我们比较后一位就可以比较出来啦。
更细致的思路与代码可以看这篇:洛谷日报#315。
我就不放代码啦。
一次比较需要 的时复。一次插入要 的时复。但还是不够优秀。
3. 正解:
我们想要的是单次比较 的时间复杂度。我们要对插入的后缀进行思考:
我们在字符串 前面插入一个字符 ,就相等于插入了一个新的后缀 。其中后缀 已经在平衡树中出现过,那么就是说后缀 在平衡树中的位置其实已经知道了,大小关系也已经确定了。那么我们是否可以利用这一点呢?
我们把每一个点设置一个虚拟权值 ,用来确定它们之间的大小关系。我们怎么判断两个后缀的大小关系呢?我们可以先判断第一个字符。如果不同就已经知道大小关系了;如果相同,那么去掉首字符之后的后缀已经在平衡树中出现过了。我们判断它们 的关系就可以知道了。因此,我们插入一个字符串的所有后缀是有顺序的。我们应该从后往前插入字符,就相当于每次插入一个新字符在字符串前。
妙啊!妙极了!边看代码边理解一下。代码如下:
inline int comp(int x,int y){ if(s[x]>s[y]||s[x]==s[y]&&trp[x+1].val>trp[y+1].val)//先看首字母,首字母相同再看去掉首字母后的权值大小 return 1; else if(s[x]==s[y]&&trp[x+1].val==trp[y+1].val) return 0; else return -1; }
那么问题就成了怎么设置 了。
1. 前驱后继取中值:
这个应该好理解。就是找到要插入的值的前驱和后继,把它们的值相加后除以 得到值。
因为是在外面找前驱后继(就是在 函数里),所以单次插入时复仍为 ,但是会爆精度。(就是如果插入的每一个后缀都比之前的后缀大,那么就会呈现“一边偏”的趋势)
2. 懒标记:
可以用 或者 等可以支持区间操作的平衡树来维护。
以 为例,我们把 插入平衡树后,对其进行 ,把字典序小于等于 的节点分裂到 上,大于 的分裂到 上。我们把 上的节点打一个懒标记,表示 上的节点的 值全部 。而 的 就是 中最大的值 。
不过这种方法因为在 函数中会跳跃访问(在函数中会访问 号节点和 号节点),而这些节点上方的标记可能并没有下放完全,所以要把从根到 和 的路径上的懒标记全部下放。一次下放需要 的时间,每一次 都需要下放,单次插入的时复为 。
这种方法虽然避免了爆精度,但是时复又回到了 + 二分时的 ,并不够优秀。
3. 正解:
我们康康解法 ,把这些权值拿出来看,我们可以发现:这一些东西构成了一棵极不平衡的平衡树。
我们是要再写一棵平衡树吗?当然不是。我们现在不是已经有了一棵平衡树了吗?我们只要把这棵平衡树好好利用。
怎么利用呢?
我们像线段树一样传两个参数 和 ,一个点的权值就是 。走向左儿子时就是 和 ,走向右儿子就是 和 。
那么每一次旋转不就会把一部分点的权值给改变了吗?
所以前置芝士就是重量平衡树啊。
我们康康重量平衡树的定义:
在插入或删除操作之后,为了保持树的平衡而重构的子树大小为均摊或期望 。
哦豁?!
就是每一次插入,需要 时间来找到插入位置,再用 时间来重构子树。时复为 ,省去常数为 。目的达到!
注意 和 不开
long long见祖宗。Upd:根据Ireliaღ大佬所说,有可能 rp 不好会导致
long long爆精度,所以保险起见最好使用double类型。我们康康代码:
void get_val(int pos,long long l,long long r){//重构 if(!pos)//判空 return ; trp[pos].val=l+r>>1; get_val(trp[pos].lson,l,trp[pos].val-1); get_val(trp[pos].rson,trp[pos].val+1,r); } void zig(int &p,long long l,long long r){ int q=trp[p].lson; trp[p].lson=trp[q].rson; trp[q].rson=p; pushup(p); pushup(q); get_val(q,l,r); p=q; } void zag(int &p,long long l,long long r){ int q=trp[p].rson; trp[p].rson=trp[q].lson; trp[q].lson=p; pushup(p); pushup(q); get_val(q,l,r); p=q; } //左右旋。不想传l和r的可以在外面get_val void ins(int &now,int pos,long long l,long long r){ if(!now){ trp[pos].key=rand(); trp[pos].val=l+r>>1; trp[pos].size=1; trp[pos].cnt=1; now=pos; return ; } if(comp(now,pos)>0){ ins(trp[now].lson,pos,l,trp[now].val-1); pushup(now); if(trp[now].key>trp[trp[now].lson].key) zig(now,l,r); } else if(comp(now,pos)<0){ ins(trp[now].rson,pos,trp[now].val+1,r); pushup(now); if(trp[now].key>trp[trp[now].rson].key) zag(now,l,r); } else{ trp[now].cnt++; pushup(now); } }
删除操作也是同理。只不过我不想写那么多的分类讨论,所以就换成了 的合并左右子树。因为 合并后期望树高仍为 ,所以合并后树高不变。合并左右子树后再重构即可。
代码如下:
int merge(int x,int y){//合并 if(!x||!y) return x+y; if(trp[x].key<trp[y].key){ trp[x].rson=merge(trp[x].rson,y); pushup(x); return x; } else{ trp[y].lson=merge(x,trp[y].lson); pushup(y); return y; } } void del(int &now,int pos,long long l,long long r){ if(!now) return ; if(comp(now,pos)==0){ if(trp[now].cnt>1) trp[now].cnt--; else{ now=merge(trp[now].lson,trp[now].rson);//合并左右子树,相当于删除节点 get_val(now,l,r);//重构 } pushup(now); return ; } if(comp(now,pos)>0) del(trp[now].lson,pos,l,trp[now].val-1); else del(trp[now].rson,pos,trp[now].val+1,r); pushup(now); }至此,后缀平衡树的插入删除操作就已经全部结束了。
怎么求出后缀数组的那些东西呢?
后缀数组有三个数组:、 和 。 表示排名为 的后缀起点, 表示后缀起点为 的排名, 表示排名为 的后缀与排名为 的后缀的 长度。
一般后缀数组都是静态问题。我们把后缀平衡树建立之后,一遍 就可以求出 和 数组啦。然后 数组就随你是用 的 还是 的遍历了。
求 和 的 代码:
int cnt; inline void dfs(int now){ if(!now) return ; dfs(trp[now].lson); sa[++cnt]=now; rk[now]=cnt; dfs(trp[now].rson); }
我们可以发现,后缀平衡树单次插入需要 的时间,有 个后缀,总共需要 的时间。
而后缀平衡树最多有 个后缀,那么其实 就只有 个节点。空间复杂度为 。
5. 与其他后缀数据结构的比较
众所周知,后缀数据结构有两大毒瘤:一是后缀数组(),另一个是后缀自动姬()。后缀树我不会,但是个人感觉应该和后缀自动姬差不多(毕竟都可以用一个算法解决)。
后缀平衡树在概念上就是 + 平衡树。所以拥有添加字符的操作。这是 所没有的。因为这种概念,所以它比 更好理解。
后缀平衡树的代码长,但是思路清晰,因此不容易写错。
后缀自动姬可以资瓷加入一个字符,而后缀平衡树不仅可以资瓷加入一个字符,还可以资瓷删除一个字符。这是后缀自动姬所没有的。
我们写 都需要一个 数组来表示一种转移边。这个 数组是依赖于字符集大小的。而后缀平衡树则不需要考虑这一点。
6. 例题
后缀数组模板题。
就直接建出后缀平衡树后 即可。
时复 。
记得吸吸氧。如果不行就晚上再交。
#pragma GCC target("avx,sse2,sse3,sse4,mmx") #include<cstring> #include<cstdlib> #include<cstdio> using namespace std; const long long INF=1e18; const int N=1e6+10; struct treap{ long long val; int lson,rson; int size; int key; int cnt; }; treap trp[N]; char s[N]; int root; inline int comp(int x,int y){ if(s[x]>s[y]||s[x]==s[y]&&trp[x+1].val>trp[y+1].val) return 1; else if(s[x]==s[y]&&trp[x+1].val==trp[y+1].val) return 0; else return -1; } inline void pushup(int pos){ int lson=trp[pos].lson,rson=trp[pos].rson; trp[pos].size=trp[lson].size+trp[rson].size+trp[pos].cnt; } inline void get_val(int now,long long l,long long r){ if(!now) return ; trp[now].val=l+r>>1; get_val(trp[now].lson,l,trp[now].val-1); get_val(trp[now].rson,trp[now].val+1,r); } inline void zig(int &p,long long l,long long r){ int q=trp[p].lson; trp[p].lson=trp[q].rson; trp[q].rson=p; pushup(p); pushup(q); get_val(q,l,r); p=q; } inline void zag(int &p,long long l,long long r){ int q=trp[p].rson; trp[p].rson=trp[q].lson; trp[q].lson=p; pushup(p); pushup(q); get_val(q,l,r); p=q; } void ins(int &now,int pos,long long l,long long r){ if(!now){ trp[pos].val=l+r>>1; trp[pos].key=rand(); trp[pos].size=1; trp[pos].cnt=1; now=pos; return ; } if(comp(now,pos)>0){ ins(trp[now].lson,pos,l,trp[now].val-1); pushup(now); if(trp[trp[now].lson].key<trp[now].key) zig(now,l,r); } else if(comp(now,pos)<0){ ins(trp[now].rson,pos,trp[now].val+1,r); pushup(now); if(trp[trp[now].rson].key<trp[now].key) zag(now,l,r); } else{ trp[now].cnt++; pushup(now); } } inline void dfs(int now){ if(!now) return ; dfs(trp[now].lson); printf("%d ",now); dfs(trp[now].rson); } int main(){ scanf("%s",s+1); int l=strlen(s+1); for(register int i=l;i>=1;i--) ins(root,i,1,INF);//从后向前 dfs(root); }然后你就可以爆切各种后缀数组题目了。
树上后缀排序。听说后缀数组很难搞这种东西,但是后缀平衡树可以轻易解决。
其他的没有什么区别,区别在于 函数上:
inline int comp(int x,int y){ if(s[x]>s[y]||s[x]==s[y]&&trp[x+1].val>trp[y+1].val) return 1; else if(s[x]==s[y]&&trp[x+1].val==trp[y+1].val) return 0; else return -1; }我们可以发现,如果字符相同,我们并不是比 与 的权值,而是应该比 和 的权值,而如果 与 权值相同,我们再比 和 的数字大小。
inline int comp(int x,int y){ if(s[x]>s[y]||s[x]==s[y]&&trp[fa[x]].val>trp[fa[y]].val) return 1; else if(s[x]==s[y]&&trp[fa[x]].val==trp[fa[y]].val&&x>y) return 1; else if(s[x]==s[y]&&trp[fa[x]].val==trp[fa[y]].val&&x==y) return 0; else return -1; }剩下的就是套模板了。
#include<iostream> #include<cstring> #include<cstdlib> using namespace std; const long long INF=1e18; const int N=1e6+10; struct treap{ long long val; int lson,rson; int size; int key; int cnt; }; treap trp[N]; char s[N]; int fa[N]; int root; inline int comp(int x,int y){ if(s[x]>s[y]||s[x]==s[y]&&trp[fa[x]].val>trp[fa[y]].val) return 1; else if(s[x]==s[y]&&trp[fa[x]].val==trp[fa[y]].val&&x>y) return 1; else if(s[x]==s[y]&&trp[fa[x]].val==trp[fa[y]].val&&x==y) return 0; else return -1; } inline void pushup(int pos){ int lson=trp[pos].lson,rson=trp[pos].rson; trp[pos].size=trp[lson].size+trp[rson].size+trp[pos].cnt; } inline void get_val(int now,long long l,long long r){ if(!now) return ; trp[now].val=l+r>>1; get_val(trp[now].lson,l,trp[now].val-1); get_val(trp[now].rson,trp[now].val+1,r); } void zig(int &p,long long l,long long r){ int q=trp[p].lson; trp[p].lson=trp[q].rson; trp[q].rson=p; pushup(p); pushup(q); get_val(q,l,r); p=q; } void zag(int &p,long long l,long long r){ int q=trp[p].rson; trp[p].rson=trp[q].lson; trp[q].lson=p; pushup(p); pushup(q); get_val(q,l,r); p=q; } void ins(int &now,int pos,long long l,long long r){ if(!now){ trp[pos].val=l+r>>1; trp[pos].key=rand(); trp[pos].size=1; trp[pos].cnt=1; now=pos; return ; } if(comp(now,pos)>0){ ins(trp[now].lson,pos,l,trp[now].val-1); pushup(now); if(trp[now].key>trp[trp[now].lson].key) zig(now,l,r); } else if(comp(now,pos)<0){ ins(trp[now].rson,pos,trp[now].val+1,r); pushup(now); if(trp[now].key>trp[trp[now].rson].key) zag(now,l,r); } else{ trp[now].cnt++; pushup(now); } } void dfs(int now){ if(!now) return ; dfs(trp[now].lson); cout<<now<<' '; dfs(trp[now].rson); } int main(){ int n; cin>>n; for(int i=2;i<=n;i++) cin>>fa[i]; cin>>s+1; for(int i=1;i<=n;i++) ins(root,i,1,INF); dfs(root); }
我不会忘记 这题时的快乐,这是我放了好久的任务列表上的题目啊。(因为柯南)其实会了 P5353 后我才发现这个小菜一碟。
先把后缀排序结果算出来,操作 可以预处理, 解决,剩下两个操作均为区间第 小的问题,套用主席树即可。具体来讲使用两棵主席树,一棵维护原树上的链,另一棵维护原树的 序。因为在一棵子树上的 序必定是连续的,所第二棵其实也是区间第 大。
#include<cstdlib> #include<cstdio> const long long INF=1e18; const int N=1e6+10; struct segment_tree{ struct hjt_node{ int lson,rson; int size; }; hjt_node hjt[40*N]; int root[N]; int tot; segment_tree(){ tot=1; } inline int copynode(int pos){ hjt[++tot]=hjt[pos]; return tot; } void init(int now,int l,int r){ if(l==r) return ; hjt[now].lson=++tot; hjt[now].rson=++tot; int mid=l+r>>1; init(hjt[now].lson,l,mid); init(hjt[now].rson,mid+1,r); } int ins(int last,int pos,int l,int r){ int now=copynode(last); hjt[now].size++; if(l==r) return now; int mid=l+r>>1; if(pos<=mid) hjt[now].lson=ins(hjt[now].lson,pos,l,mid); else hjt[now].rson=ins(hjt[now].rson,pos,mid+1,r); return now; } int query(int last,int now,int key,int l,int r){ if(l==r) return l; int size=hjt[hjt[now].lson].size-hjt[hjt[last].lson].size; int mid=l+r>>1; if(key<=size) return query(hjt[last].lson,hjt[now].lson,key,l,mid); else return query(hjt[last].rson,hjt[now].rson,key-size,mid+1,r); } }; struct treap{ long long val; int lson,rson; int size; int key; int cnt; }; struct edge{ int from,to; int nxt; }; segment_tree hjt1,hjt2; treap trp[N]; edge e[N]; int fa[N],a[N],last[N],sa[N],rk[N],rev[N],dfn[N],size[N]; int root,tot,cnt,num; inline void add(int from,int to){ tot++; e[tot].from=from; e[tot].to=to; e[tot].nxt=last[from]; last[from]=tot; } inline bool comp(int x,int y){ if(a[x]!=a[y]) return a[x]>a[y]; else if(fa[x]&&fa[y]&&fa[x]!=fa[y]) return trp[fa[x]].val<trp[fa[y]].val; else return x>y; } inline void pushup(int pos){ int lson=trp[pos].lson,rson=trp[pos].rson; trp[pos].size=trp[lson].size+trp[rson].size+trp[pos].cnt; } void get_val(int now,long long l,long long r){ if(!now) return ; trp[now].val=l+r>>1; get_val(trp[now].lson,l,trp[now].val-1); get_val(trp[now].rson,trp[now].val+1,r); } void zig(int &p,long long l,long long r){ int q=trp[p].lson; trp[p].lson=trp[q].rson; trp[q].rson=p; pushup(p); pushup(q); get_val(q,l,r); p=q; } void zag(int &p,long long l,long long r){ int q=trp[p].rson; trp[p].rson=trp[q].lson; trp[q].lson=p; pushup(p); pushup(q); get_val(q,l,r); p=q; } void ins(int &now,int pos,long long l,long long r){ if(!now){ trp[pos].key=rand(); trp[pos].val=l+r>>1; trp[pos].size=1; trp[pos].cnt=1; now=pos; return ; } if(!comp(now,pos)){ ins(trp[now].lson,pos,l,trp[now].val-1); pushup(now); if(trp[now].key>trp[trp[now].lson].key) zig(now,l,r); } else{ ins(trp[now].rson,pos,trp[now].val+1,r); pushup(now); if(trp[now].key>trp[trp[now].rson].key) zag(now,l,r); } } void get_sa(int now){ if(!now) return ; get_sa(trp[now].lson); sa[++cnt]=now; rk[now]=cnt; get_sa(trp[now].rson); } void dfs(int u){ rev[++num]=u; dfn[u]=num; size[u]=1; for(int i=last[u];i;i=e[i].nxt){ int v=e[i].to; dfs(v); size[u]+=size[v]; } } int main(){ int n,m; scanf("%d%d",&n,&m); for(int i=2;i<=n;i++){ scanf("%d",&fa[i]); add(fa[i],i); } for(int i=1;i<=n;i++) scanf("%d",&a[i]); for(int i=1;i<=n;i++) ins(root,i,1,INF); get_sa(root); hjt1.init(hjt1.root[0]=1,1,n); for(int i=1;i<=n;i++) hjt1.root[i]=hjt1.ins(hjt1.root[fa[i]],rk[i],1,n); dfs(1); hjt2.init(hjt2.root[0]=1,1,n); for(int i=1;i<=n;i++) hjt2.root[i]=hjt2.ins(hjt2.root[i-1],rk[rev[i]],1,n); int opt,x,y; while(m--){ scanf("%d",&opt); if(opt==1){ scanf("%d",&x); printf("%d\n",rk[x]); } else if(opt==2){ scanf("%d%d",&x,&y); printf("%d\n",sa[hjt1.query(hjt1.root[0],hjt1.root[x],y,1,n)]); } else{ scanf("%d%d",&x,&y); printf("%d\n",sa[hjt2.query(hjt2.root[dfn[x]-1],hjt2.root[dfn[x]+size[x]-1],y,1,n)]); } } }
这题我脑抽在 后加了分号结果一直没调出来…这一题是在字符串后面加入一个字符,我们要把它转换成在字符串前面加入一个字符。
怎么转换?
就是把整个字符串颠倒。
其实就是 函数变成这样:
inline int comp(int x,int y){ if(s[x]>s[y]||s[x]==s[y]&&trp[x-1].val>trp[y-1].val) return 1; else if(s[x]==s[y]&&trp[x-1].val==trp[y-1].val) return 0; else return -1; }因为转换之后,我们可以认为它维护的是原字符串的前缀,只不过是从最后一位开始比较。我们比较最后一位之后,我们就要比较倒数第二位。即为 和 。
假设原串为 ,查询的串为 ,那么查询我们可以转换为有多少个 的后缀以 作为前缀。即有多少 的后缀以 作为前缀。其中 为 的反串, 为 的反串。
我们可以在 后加入极大值,在后缀平衡树中查询排名为 ,再把上一个字符 后查询排名设为 。答案就是 。
因为查询的字符串并没有在平衡树中出现过,所以不能使用原来的那种方法比较。我们只能暴力比较。时复为 。数据范围告诉我们 为 ,所以查询时复为
放上代码:
#include<algorithm> #include<iostream> #include<cstring> using namespace std; const long long INF=1e18; const int N=1e6+10; struct treap{ long long val; int lson,rson; int size; int key; int cnt; }; treap trp[N]; char s[N],str[N],opt[10]; int root; void decode(char *ch,int mask){ int l=strlen(ch); for(int i=0;i<l;i++){ mask=(mask*131+i)%l; char t=ch[i]; ch[i]=ch[mask]; ch[mask]=t; } } inline int comp(int x,int y){ if(s[x]>s[y]||s[x]==s[y]&&trp[x-1].val>trp[y-1].val) return 1; else if(s[x]==s[y]&&trp[x-1].val==trp[y-1].val) return 0; else return -1; } bool check(int pos){ for(int i=1,j=pos;str[i];i++,j--)//因为是逆序,所以j要倒着遍历 if(str[i]>s[j]) return false; else if(s[j]>str[i]) return true; } inline void pushup(int pos){ int lson=trp[pos].lson,rson=trp[pos].rson; trp[pos].size=trp[lson].size+trp[rson].size+trp[pos].cnt; } inline void get_val(int now,long long l,long long r){ trp[now].val=l+r>>1; if(trp[now].lson) get_val(trp[now].lson,l,trp[now].val-1); if(trp[now].rson) get_val(trp[now].rson,trp[now].val+1,r); } void zig(int &p,long long l,long long r){ int q=trp[p].lson; trp[p].lson=trp[q].rson; trp[q].rson=p; pushup(p); pushup(q); get_val(q,l,r); p=q; } void zag(int &p,long long l,long long r){ int q=trp[p].rson; trp[p].rson=trp[q].lson; trp[q].lson=p; pushup(p); pushup(q); get_val(q,l,r); p=q; } void ins(int &now,int pos,long long l,long long r){ if(!now){ trp[pos].val=l+r>>1; trp[pos].key=rand(); trp[pos].size=1; trp[pos].cnt=1; now=pos; return ; } if(comp(now,pos)>0){ ins(trp[now].lson,pos,l,trp[now].val-1); pushup(now); if(trp[trp[now].lson].key<trp[now].key) zig(now,l,r); } else if(comp(now,pos)<0){ ins(trp[now].rson,pos,trp[now].val+1,r); pushup(now); if(trp[trp[now].rson].key<trp[now].key) zag(now,l,r); } else{ trp[now].cnt++; pushup(now); } } int rnk(int now){ if(!now) return 1; else if(check(now)) return rnk(trp[now].lson); else return rnk(trp[now].rson)+trp[trp[now].lson].size+trp[now].cnt; } int main(){ int n; cin>>n; cin>>s+1; int len=strlen(s+1),l; for(int i=1;i<=len;i++) ins(root,i,1,INF); int mask=0,ans; while(n--){ cin>>opt+1>>str+1; decode(str+1,mask); l=strlen(str+1); if(opt[1]=='A'){ for(int i=len+1;i<=len+l;i++){ s[i]=str[i-len]; ins(root,i,1,INF); } len+=l; } else{ reverse(str+1,str+l+1); str[l+1]='C'; str[l+2]='\0'; ans=rnk(root); str[l]--; ans-=rnk(root); mask^=ans; cout<<ans<<'\n'; } } }
终于到了模板题。其实就比上一道题多了一个删除操作而已…
加上删除操作就可以了。
放上代码:
#include<algorithm> #include<iostream> #include<cstring> #include<cstdlib> using namespace std; const long long INF=1e18; const int N=8e5+10; struct treap{ long long val; int lson,rson; int size; int cnt; int key; }; treap trp[N]; char s[N],ty[11],str[N]; int root; void decode(char *ch,int mask){ int l=strlen(ch); for(int i=0;i<l;i++){ mask=(mask*131+i)%l; char t=ch[i]; ch[i]=ch[mask]; ch[mask]=t; } } inline int comp(int x,int y){ if(s[x]>s[y]||s[x]==s[y]&&trp[x-1].val>trp[y-1].val) return 1; else if(s[x]==s[y]&&trp[x-1].val==trp[y-1].val) return 0; else return -1; } inline bool check(int pos){ for(int i=1,j=pos;str[i];i++,j--) if(str[i]<s[j]) return true; else if(str[i]>s[j]) return false; } inline void pushup(int pos){ int lson=trp[pos].lson,rson=trp[pos].rson; trp[pos].size=trp[lson].size+trp[rson].size+trp[pos].cnt; } void dfs(int pos,long long l,long long r){ int lson=trp[pos].lson,rson=trp[pos].rson; trp[pos].val=l+r>>1; if(lson) dfs(lson,l,trp[pos].val-1); if(rson) dfs(rson,trp[pos].val+1,r); } void zig(int &p,long long l,long long r){ int q=trp[p].lson; trp[p].lson=trp[q].rson; trp[q].rson=p; pushup(p); pushup(q); dfs(q,l,r); p=q; } void zag(int &p,long long l,long long r){ int q=trp[p].rson; trp[p].rson=trp[q].lson; trp[q].lson=p; pushup(p); pushup(q); dfs(q,l,r); p=q; } int merge(int x,int y){ if(!x||!y) return x+y; if(trp[x].key<trp[y].key){ trp[x].rson=merge(trp[x].rson,y); pushup(x); return x; } else{ trp[y].lson=merge(x,trp[y].lson); pushup(y); return y; } } void ins(int &now,int pos,long long l,long long r){ if(!now){ trp[pos].lson=trp[pos].rson=0; trp[pos].key=rand(); trp[pos].val=(l+r)/2; trp[pos].size=1; trp[pos].cnt=1; now=pos; return ; } if(comp(now,pos)>0){ ins(trp[now].lson,pos,l,trp[now].val-1); pushup(now); if(trp[now].key>trp[trp[now].lson].key) zig(now,l,r); } else if(comp(now,pos)<0){ ins(trp[now].rson,pos,trp[now].val+1,r); pushup(now); if(trp[now].key>trp[trp[now].rson].key) zag(now,l,r); } else{ trp[now].cnt++; pushup(now); } } void del(int &now,int pos,long long l,long long r){ if(!now) return ; if(comp(now,pos)==0){ if(trp[now].cnt>1) trp[now].cnt--; else{ now=merge(trp[now].lson,trp[now].rson); if(now) dfs(now,l,r); } return ; } if(comp(now,pos)>0) del(trp[now].lson,pos,l,trp[now].val-1); else del(trp[now].rson,pos,trp[now].val+1,r); pushup(now); } int rnk(int now){ if(!now) return 1; else if(check(now)) return rnk(trp[now].lson); else return rnk(trp[now].rson)+trp[trp[now].lson].size+trp[now].cnt; } int main(){ int n; cin>>n; cin>>s+1; int len=strlen(s+1); for(int i=1;i<=len;i++) ins(root,i,1,INF); int l,x; int ans; int mask=0; while(n--){ cin>>ty+1; switch(ty[1]){ case 'A': cin>>str+1; decode(str+1,mask); l=strlen(str+1); for(int i=len+1;i<=len+l;i++){ s[i]=str[i-len]; ins(root,i,1,INF); } len+=l; break; case 'D': cin>>x; for(int i=len;i>len-x;i--) del(root,i,1,INF); len-=x; break; case 'Q': cin>>str+1; decode(str+1,mask); int l=strlen(str+1); reverse(str+1,str+l+1); str[l+1]='Z'+1; str[l+2]='\0'; ans=rnk(root); str[l]--; ans-=rnk(root); mask^=ans; cout<<ans<<'\n'; break; } } }
插入:可持久化后缀平衡树
貌似可以,又貌似不行…
反正我是不会啦。有谁可以教一下我?
7. 参考资料
陈立杰的论文:重量平衡树和后缀平衡树在信息学奥赛中的应用。
YoungNeal的总结:[总结] 后缀平衡树学习笔记。
Ireliaღ的题解:题解 P6164 【【模板】后缀平衡树】。
-
- 1