1 条题解
-
0
自动搬运
来自洛谷,原作者为

lgswdn_SA
舞台少女,每日进化中搬运于
2025-08-24 21:57:25,当前版本为作者最后更新于2020-03-26 13:27:00,作者可能在搬运后再次修改,您可在原文处查看最新版自动搬运只会搬运当前题目点赞数最高的题解,您可前往洛谷题解查看更多
以下是正文
希望写的能比别的题解更加详细
分析
贝西需要跑到树的叶节点才行。我们不妨现设贝西的出发点为根。
我们要做的是“封锁点”,就是在站在一个点上阻止贝西通行。一旦准时站在点 上,就等于封锁了整个子树内的点,因为贝西将无法进入这棵子树内部。目标是封锁所有叶节点。
我们称一个农民要站着封锁子树的点 为封锁点(自己瞎扯的名字)。
所以我们现在要合理地安排封锁点。由贪心的想法可知,我们做到每个叶节点只被一个封锁点封锁。
封锁点的规则
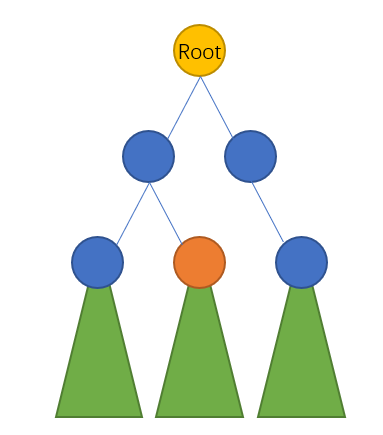
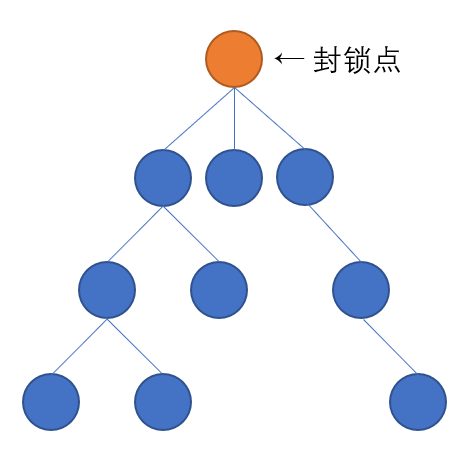
我们先看这张图。我们希望确定橙点能不能成为一个封锁点。封锁点要求能成功准时地封锁住贝西,所以一定需要存在一个出口,使得农夫能在贝西抵达并穿过封锁点进入子树前到达封锁点。
因为可以说准时到达封锁点是让贝西不进入子树内地叶节点的唯一机会。一旦比贝西晚到达,你就永远也追不上它了,它会长驱直入逃走。
所以我们必须制定这个规则。
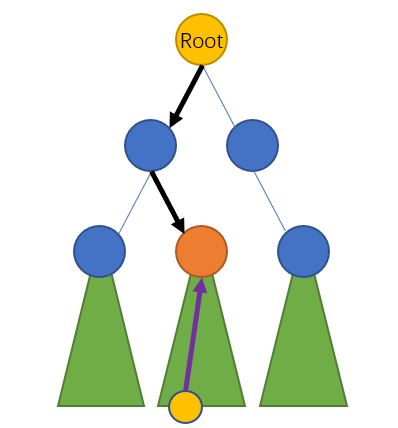
黄色小点是最接近封锁点的出口,紫色路径是农夫到达封锁点的路径,黑色路径是贝西试图到达封锁点然后长驱直入逃跑的路径。
显然,我们需要紫色路径长度黑色路径长度。
还有,为了保证是最优解,一旦父亲可以做封锁点,那么儿子就不用再做封锁点了。
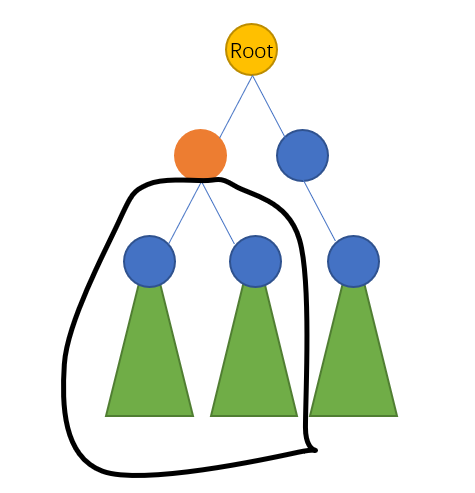
我们假设橙点是一个封锁点。因为父亲已经封锁了整个子树,所以儿子就不用(橙点的两个子节点)就不用再作为封锁点浪费农民资源了。
于是,我们得到了一个点 应不应该是封锁点的条件:
且其中 代表离 最近的叶节点, 代表两点距离。
算法
对于每一个根节点(就是出发点):
先暴力 dfs 求出 和 和 和 ,然后判断是不是一个封锁点。如果是的,ans++。优化
上述算法是 的,本质问题是每次要确定一个根。
但是,我们发现其实 都是和根无关的,在无根情况下可以做出来。那么罪魁祸首就是 数组。所以我们要换一种统计确定封锁点的方式。
我们试图要去掉的影响。
试想,如果我们不计算 , 会是什么?
下图中蓝色的点是封锁点,绿色三角代表了这棵树(看起来更像一个山……不管了)
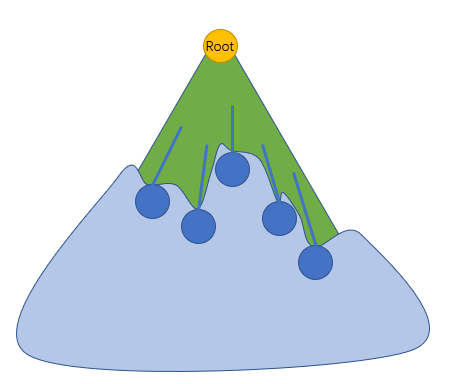
那么被淡蓝色覆盖到的部分都会被统计到。那么我们保持这些点都被统计的状态,需要改变这些点的权值,让这些被覆盖到的点的权值之和=封锁点的数量。
这个问题看上去很棘手啊。不过我们对其进行分子树考虑。
(我们先不考虑封锁点是根节点的情况)
我们需要子树权值和是 ,而且权值只与自己有关。
再具体一点,肯定存在一些操作,使得一些点的权值和为 (否则没法做)。我们可以想到树上差分,因为两个节点权值 , LCA 权值 ,构成了天然的抵消操作。
这样,我们只需要子树中的叶节点的权值为 ,其他节点的权值为 儿子数量,也就是 这个节点的度数。
所以,每个节点的权值是这个节点的度数()。所以,对于每个根节点,我们要求
其中里面的东西除了 都和 无关,而 是 的路径长度,所以就是统计有多少点对 满足 。
其实,上面的东西,就是树形差分的一些基础的公式的东西。
上述可以用点分治实现,复杂度是
这种不等式点对的点权统计可以用这种点分治模板实现:我的博客里面的模板题
对于
cal函数的实现:(下面请你忘掉 原来的含义,记住他的新的含义)
我们假设为在以 为根的深度,于是题目的条件变成了
先在 update 的时候更新数组 , ,然后用结构体顺便把
在 cal 中先排个序,然后从左到右遍历 ,对于每个,满足条件的 是个前缀,于是动态维护前缀和就行了。
代码中用 代表
重要的事情 dfz 函数的 find_root 里面和别的一些题解不一样,这些区别影响到了代码的运行速度。具体注意事项参考这个讨论的第2,3页某金钩大佬的话,顺便%他
#include<bits/stdc++.h> using namespace std; const int N=7*1e5; struct edge{int to,nxt,w;}e[N*2]; int hd[N],tot; void add(int u,int v,int w){e[++tot]=(edge){v,hd[u],w};hd[u]=tot;} int n,ans[N]; int d[N],deg[N],p[N],dp[N],sz[N]; void dfs_down(int u,int fa){ sz[u]=1; for(int i=hd[u],v;i;i=e[i].nxt) if((v=e[i].to)!=fa){ d[v]=d[u]+e[i].w,deg[v]++,deg[u]++; dfs_down(v,u); sz[u]+=sz[v]; if(dp[v]+e[i].w<=dp[u]) p[u]=p[v],dp[u]=dp[v]+e[i].w; } if(deg[u]==1) p[u]=u,dp[u]=0; } void dfs_up(int u,int fa){ for(int i=hd[u],v;i;i=e[i].nxt) if((v=e[i].to)!=fa){ if(dp[u]+e[i].w<=dp[v]) p[v]=p[u],dp[v]=dp[u]+e[i].w; dfs_up(v,u); } } int mx[N]; bool vst[N]; int find_root(int u,int fa,int cnt,int root){ sz[u]=1,mx[u]=0; for(int i=hd[u],v;i;i=e[i].nxt) if((v=e[i].to)!=fa&&!vst[v]){ root=find_root(v,u,cnt,root); sz[u]+=sz[v]; mx[u]=max(mx[u],sz[v]); } mx[u]=max(mx[u],cnt-sz[u]); if(mx[u]<=mx[root]) root=u; return root; } struct as{int id,dis;}ca[N]; struct bs{int val,dis;}cb[N]; bool cmpa(const as&a,const as&b){return a.dis<b.dis;} bool cmpb(const bs&a,const bs&b){return a.dis<b.dis;} int cnt; void update(int u,int fa){ ca[++cnt]=(as){u,d[u]},cb[cnt]=(bs){2-deg[u],dp[u]-d[u]}; for(int i=hd[u],v;i;i=e[i].nxt) if((v=e[i].to)!=fa&&!vst[v]){ d[v]=d[u]+e[i].w; update(v,u); } } void cal(int u,int base,int sig,int ret=0){ d[u]=base; cnt=0; update(u,0); sort(ca+1,ca+cnt+1,cmpa),sort(cb+1,cb+cnt+1,cmpb); int j=0,sum=0; for(int i=1;i<=cnt;i++){ while(j<cnt&&cb[j+1].dis<=ca[i].dis) j++,sum+=cb[j].val; ans[ca[i].id]+=sig*sum; } } int dfz(int u,int wtcl){ vst[u]=1; cal(u,0,1); for(int i=hd[u],v,tmp;i;i=e[i].nxt) if(!vst[(v=e[i].to)]){ cal(v,e[i].w,-1); int root=find_root(v,u,tmp=(sz[v]>sz[u]?wtcl-sz[u]:sz[v]),0); dfz(root,tmp); } } int main(){ scanf("%d",&n); for(int i=1,u,v,w;i<n;i++) scanf("%d%d",&u,&v),add(u,v,1),add(v,u,1); memset(dp,0x3f,sizeof(dp)),memset(mx,0x3f,sizeof(mx)); dfs_down(1,0); dfs_up(1,0); int root=find_root(1,0,n,0); dfz(root,n); for(int i=1;i<=n;i++) printf("%d\n",deg[i]==1?1:ans[i]); return 0; }
- 1