1 条题解
-
0
自动搬运
来自洛谷,原作者为

皎月半洒花
在那之前,你要多想。搬运于
2025-08-24 21:48:13,当前版本为作者最后更新于2018-02-08 23:41:28,作者可能在搬运后再次修改,您可在原文处查看最新版自动搬运只会搬运当前题目点赞数最高的题解,您可前往洛谷题解查看更多
以下是正文
** 这篇博客我打算皮一下qwq,适合初学者阅读(因为讲的是在太细了) **
一、首先理解字符串操作的意义:
没意义其实字符串操作的意义是很浅显的,比如百度的推荐搜索啊,比如查找比对一篇题解里有多少个相同或者不同的脏字然后再根据其数量、恶劣程度决定用多大的刀将博主掉。。。所以字符串操作很重要啊喂。
再来考虑时间:如果百度对于一个人的一次“常搜”推荐需要,那么对于全国网友来说,同时上网的人群基数很高,那么如果服务器性能不好的话,怕不是要三星 ???
所以啊,打造高效的字符串算法是很有必要滴!
二、言归正传,浅析字符串哈希
哈希其实是所有字符串操作中,笔者认为最简单的操作了(except输入输出qwq)。哈希的过程,其实可以看作对一个串的单向加密过程,并且需要保证所加的密不能高概率重复(就像不能让隔壁老王轻易地用它家的钥匙打开你家门一样qwq),通过这种方式来替代一些很费时间的操作。
比如,最常见的,当然就是通过哈希数组来判断几个串是否相同(洛谷P3370)。此处的操作呢,很简单,就是对于每个串,我们通过一个固定的转换方式,将相同的串使其的“密”一定相同,不同的串 尽量 不同。
此处有人指出:那难道不能先比对字符串长度,然后比对ASCLL码之和吗?事实上显然是不行的(比如ab和ba,并不是同一个串,但是如是做却会让其认为是qwq)。这种情况就叫做**冲突**,并且在如此的单向加密哈希中,冲突的情况在所难免(bzoj就有这种让你给出一组样例,使得一段哈希代码冲突的题,读者可以尝试尝试)。
而我们此处介绍的,即是最常见的一种哈希:进制哈希。进制哈希的核心便是给出一个固定进制,将一个串的每一个元素看做一个进制位上的数字,所以这个串就可以看做一个进制的数,那么这个数就是这个串的哈希值;则我们通过比对每个串的的哈希值,即可判断两个串是否相同
奉上代码(单哈希):
#include<iostream> #include<cstring> #include<algorithm> #include<cstdio> using namespace std; typedef unsigned long long ull; ull base=131; ull a[10010]; char s[10010]; int n,ans=1; int prime=233317; ull mod=212370440130137957ll; ull hashe(char s[]) { int len=strlen(s); ull ans=0; for (int i=0;i<len;i++) ans=(ans*base+(ull)s[i])%mod+prime; return ans; } int main() { scanf("%d",&n); for(int i=1;i<=n;i++) { scanf("%s",s); a[i]=hashe(s); } sort(a+1,a+n+1); for(int i=1;i<n;i++) { if(a[i]!=a[i+1]) ans++; } printf("%d",ans); }当然,再好的哈希也会有冲突,此时有两种做法可以解决或者降低哈希冲突的可能性
1、无错哈希
其实原理很简单,就是我们要记录每一个已经诞生的哈希值,然后对于每一个新的哈希值,我们都可以来判断是否和已有的哈希值冲突,如果冲突,那么可以将这个新的哈希值不断加上一个大质数,直到不再冲突(比如somebody’s birthday qwq)。
先贴代码:
for(int i=1;i<=m;i++)//m个串 { cin>>str;//下一行的check为bool型 while(check[hash(str)])hash[i]+=19260817; hash[i]+= hash(str) ; }正如下图(亲手做的
英文高逼格):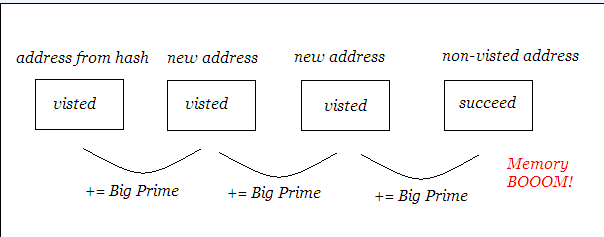
但是,这种方法类似桶查找,但是桶查找的弊端2就会很恶心——数据过大,数组无能为力来支持上亿个空间(弊端1是由于数据具有跳跃性,浪费最后的统计次数,但在此不是特别明显,就当我皮了一下qwq)
2、多重哈希
这其实就是你用不同的两种或多种方式哈希,然后分别比对每一种哈希值是否相同——显然是增加了空间和时间,但也确实增加了其正确性。
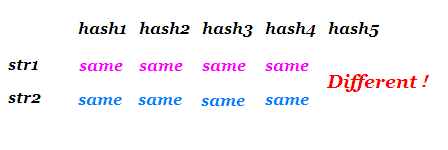
下面皮一个哈希自动机qwq(不用百度了,名字自己起的)
//哈希自动机,需要二维hash数组 for伪代码排序,用来使哈希值单调(更好判断相/不同的数量) for(int i=1;i<=m;i++){ check=1; for(int j=1;j<=qwq;j++)//皮一下 if(hash[j][i]==hash[j][i+1]){check=0;break;} if(check)ans++;//此为判断相同个数 }三、字典树浅析
1、简要介绍
首先要知道,字典树是一种假想数据结构(数据结构不都是 假想的吗qwq),那么问题来了——为什么是要用字典树呢?为什么不用类似字典链表之类的东西呢?很简单,所有树形结构 都有一个基本特点,就是
元素与元素间的关系为继承的一对多关系。
拿字典树来说,每一个元素都可以有几个子元素,作为它之后的字母;而倘若要比对两个字符串是否相同,只需要比对在这棵字典树上,这两个串最后一个元素的祖先链(即前缀)是否相同,并且对于祖先链来说,并不用逐个比较,只需要记录访问就行
比如下图就是一棵,这里用颜色区分单词路径上的点

2、字典树基础与如何建树(插入操作)
首先,关于字典树,我们一般不是用点来存储字符的,而是用边——为什么呢?之后再说(十分皮地卖个关子qwq)。
重新首先,一般来说,字典树是不会使用根节点的,原因很浅显,因为根节点的个数决定究竟有几棵字典树,而通常字典树是只有一棵的,否则产生森林会很麻烦(qwq你皮你就splay,并且如果有森林的话应该叫做“字典森林”啊喂)。
但是我们要知道,并不是一个题中所有的串都有公共前缀(肯定不会的吧qwq),可如果根节点唯一,就代表他们一定有公共前缀,并且公共前缀的长度必定大于等于1。
其次,字典树中每个节点的子节点数量都肯定会小于某个数。
如果字典树里都是小写字母,那么“某个数”就是26;如果大小写都有,“某个数”就应该是52(证明过程:显然);
并且每个节点的所有的边都不同,这条性质可以便于我们判断在某一棵字典树到底有没有某条链:只要前缀不符合,就不需要再判断,因为必然没有(同一深度、同一父亲,边与边必定互异)
在这里,我选择用结构体来存树,具体解释见注释:
//建树(其实就是存点啦) struct nodes{ int son[26]; //此处只考虑小写字母字典树 bool mark; // 此为标记,作用下面说 }trie[10001]; int root=0,num=0; //根节点永久为0 qwq bool insert_check(char *str) { int position=root;//初始化位置,跟深度没有直接关系 for(int i=0;str[i];i++) { int symbol=(int)str[i]-'a'; /*此处实际是因为我们的trie都是存int的,如果贸然存char会 很别扭qwq,并且此处由于都是小写字母,所以 -‘a’ ,如果 存了别的类型的字符,需要特判,保证字符容易确定 */ if(!trie[position].son[symbol]) //还没有被编号 trie[position].son[symbol]=++num;//编一个号 position=trie[position].son[symbol] ; //更新迭代位置,直到字符链的最末端 } int temp=trie[position].mark; trie[position].mark =1; //将这条链的最末端置为1,如果还有重复的串,那么一定会出现 //最末端相同 ;反之,最末端节点的mark相同也可以推出链相同, //借此来判断串是否相同 return temp!=0; /*最后说一下为什么要编号:我们根据程序可以看出,字符串是 按秩插入树,所以一条链上的编号肯定满足单调,便于我们查找 和比对*/ }于是便可以通过这种方式比对字符串,期望时间复杂度O(n)大多用于比对。
3、关于字典树的查找
查找前缀比较好写,只需要一边判断是否符合要求,一边判断是否继续迭代即可。
int root=0; bool find(char* str) { int pos=root; for(int i=0;str[i];i++) { int x=str[i]-'a'; if(trie[pos].son[x]==0)return false; //如果在建完树之后这个点还没有被编号, //那么就肯定不存在这条链。(互异性) pos=trie[pos].son[x] ;//继续迭代 } return true; }其实查询单词和查询前缀差别不大,只是我们每次都需要维护一个(),存在单词链的末尾。
每当一个新字符已经被标记时(即所查询单词的这个字母及其前缀都在树的某条链上),我们使这个字符异于它祖先们的,最后判断**该条匹配链结尾字符的是否异于链上其他字符的**即可判断是否有这个单词(如果没有的话,末尾的肯定与链上其他的相同啊qwq)
至于前缀出现次数,很简单,只要将每一个前缀的出现次数存到它相连的子节点,最后输出前缀最后一个字符所带的次数即可(可以用数组维护,也可以直接写在结构体里)
好啦,就是这样,希望对大家有所帮助
日拱一卒,功不唐捐!
- 1