1 条题解
-
0
自动搬运
来自洛谷,原作者为

jjsnam
I'm no good at goodbyes.搬运于
2025-08-24 21:47:40,当前版本为作者最后更新于2022-05-25 14:39:59,作者可能在搬运后再次修改,您可在原文处查看最新版自动搬运只会搬运当前题目点赞数最高的题解,您可前往洛谷题解查看更多
以下是正文
写在前面
这是学校字符串哈希算法的作业,也是我第一个自己 AC 的有关字符串算法的紫题。同时,我被这道题坑的很惨,所以写题解出来记录一下。
这道题让人又爱又恨。它的槽点很多,但它的确是一道好题,我在写题解的时候又在一遍遍不停的驳斥自己的思路,迭代自己的代码。花费了这么多时间,但是我也收获了很多。
首先说明,这道题哈希的严格正确做法跑的比较慢,但是应该不用像楼上需要吸氧,本代码存在一定不严谨性(文章中也会提及严谨做法),最慢是 300ms 多(看不上的神犇们可以去看楼上 KMP+Tire 的解法,但是本蒟蒻不会),但因为这道题数据很弱,我们
阉割后的代码跑的飞快,吸氧后碾压其他做法,目前最优解 rank 1。吐槽
这道题槽点很多。我来罗列一下:
-
题面的 markdown 炸了(或者根本没用)。
-
算法标签一塌糊涂(字符串跟数论有个毛关系?)。
-
数据范围有问题。具体来说,数据总体的范围给的太小,导致我一直在 TLE 和 RE。后来白嫖到了这道题在 BZOJ 的数据,题目描述中会对数据范围进行修正。
-
数据太弱。数据中的 , 全部相等,这导致它的难度只配是绿到蓝。如果保证了两数不相等,才满足蓝题以上。其次,它要作为紫题还需要有卡掉一些无脑做法的 hack,后文会提及。
就这些坑点让我花费了大把时间,真气死哦嘞!
前置知识
-
字符串哈希,Hash
-
STL:unordered_map 使用方法
-
快速幂
题目描述(戳这里查看原题)
给定两组字符串,保证每组中的字符串长度都相等。
从两组字符串中各拿出一个字符串组成新的字符串(保证新的字符串长度是偶数),求将这个新的字符串从中间断开后,满足前后两个子串互为双旋转字符串的方案数。
双旋转字符串:即将字符串旋转后相等(可以当做字符串在粘成一圈的纸带上,我们转纸带,出现的字符串都是双旋转字符串)。
举个例子:字符串 的双旋转字符串包括 、、,以及它自己。其中,两组字符串中字符串的个数分别为 、(为了方便我们引用为 、),每组字符串的长度分别为 、。
满足:,,,极端情况下保证 。(数据范围已更正)
正文
其实有关字符串的题目思维难度并没有像图论、动态规划那样高。它的特点就在于要理清思路,然后正确的把代码写出来,就好似一个大模拟。这类题的代码实现难度普遍会高一些。
分析
写代码之前要有明确的思路,所以我们首先分析样例。
比如,我们取出集合 中的第一串 ,那么根据定义,它将作为新字符串前面的一部分。接下来我们要考虑怎么在 中找到后面的那个字符串。
新的字符串保证长度 。那么我们从中间断开后,两段字符串的长度都是 。又因为我们从 中取出来的串长度为 ,所以我们能确定新的字符串断开后的两个串分别为:、(是我们要匹配的部分,它需要在字符串集合 中)。
对于断开后的前串,我们可以得到它的双旋转字符串:
- 、、、、
通过观察发现,这些双旋转字符串中只有 的前缀与我们需要匹配的后串 的前缀相同,都是 。这就说明只有当后串等于 时,后串是前串的双旋转字符串。
因此,在这种情况下,我们推出 。通过查询字符串集合 ,我们发现内容为 的字符串有 个,则这种情况对答案的贡献是 。
同理我们再枚举 中的其他字符串,一个一个匹配,最后把所有贡献累加起来的答案等于 。
思路
通过刚才的分析,其实做法就是很显然的事情了。
由于 ,则我们枚举 中的字符串一定可以确定新字符串的前串以及多出来被断在后串的一部分字符串 (其中 的长度可以为 0,而且 一定是后串的一个前缀)。既然有了前串,那我们只需要枚举所有前串的双旋转字符串 ,通过匹配 的前缀和后串的前缀 是否相等,如果相等就说明后串可以是 ,那么我们也就确定了需要在字符串集合 中匹配的字符串 (满足 ,这里的加号是字符串合并)。这样我们只用知道 中有多少 就可以计算对答案的贡献了。
具体实现
思路很简单,接下来就是代码实现了,这里需要的知识比较多,我们一步一步来。
① 如何枚举一个字符串 的所有双旋转字符串?
这里我们联想一下区间 DP。如果是一个环型区间 DP,你会怎么做?
那自然是倍长。我们将 复制一次,就得到了一个长度是 两倍,内容是 重复两次的新字符串。然后我们像一个滑块一样,遍历这个新的字符串,每次找到一个起点,取长度与 长度相同的新的字符串的子串,这个子串就是 的一个双旋转字符串。
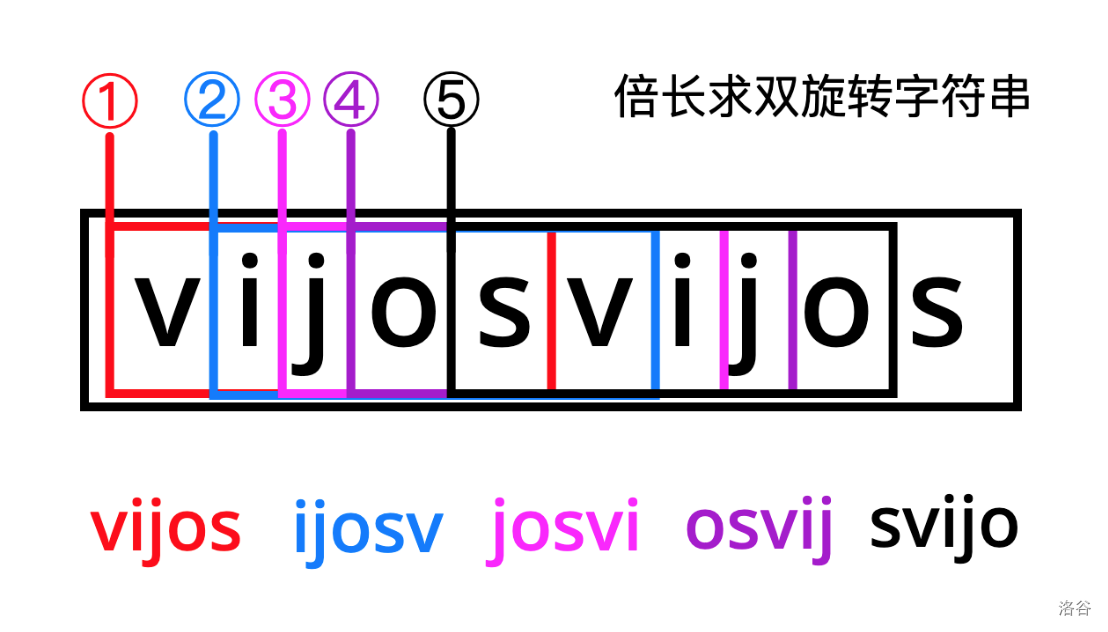
② 怎样匹配前缀?
这个就简单提一嘴,毕竟做到紫题肯定是对字符串哈希很了解的大佬们了。
我们通过 unsigned long long 自动溢出的性质,用它作为一个大模数,通过对一个字符串 乘以一个基底,将这个字符串哈希(我们定义这个哈希数组为 )。
-
建立哈希数组:
。
其中 , 值一般取 。 -
查询哈希数组中 的哈希值:
。
那么比较两个前缀的哈希值,我们可以将比对项的哈希值设为 ,之后在枚举双螺旋字符串时每回只取前面与比对项长度相同的子串作为前缀,求得它的哈希值与 比较即可。相等就是两个前缀相等,证明后串存在是该双旋转字符串的可能性,对答案有贡献。
③ 比对前缀相等后,如何求得待匹配串 ?
char 固然可以做,但是使用 更加的好写,看起来也更
优雅。我们设比对成功后双旋转字符串 的起始字符是 ,末字符是 ,比对前缀 的长度是 。那么此时满足条件的后串一定等于 。而 中 是比对的前缀,那么 就是剩下的部分,也就是 中 这一部分。
具体操作可以用
substr()函数解决。④ 得到匹配串 后,如何找到其在 中的个数?
可能有人会想用 multiset 或者 map,但是他们的单次查询时间复杂度都是 ,对于 的数据还是不太友好(因为我一开始就用的这个,最后一直在 TLE)。
相比之下,我强烈推荐 unordered_map。它的内部实现也是哈希,但是平均时间复杂度是 ,一般情况下的效率会比 multiset 高很多。
然后就很显然了,初始读入 的时候我们就把所有字符串都哈希并添加到一个 unordered_map 中,用的时候直接查找就好。
细节
一般在哈希的时候我们要预处理出基底的所有幂,以便查询,但是我们观察这题,需要那么多幂吗?
对于已知的 、,我们可以确定出查询一个双旋转字符串的长度,也就得出了需要 。
比较前缀,我们知道长度是 ,需要 。
之后要查找 中的匹配串,长度为 ,需要 。所以总共只需要 个幂,开始时快速幂即可。
坑点
首先声明,弱鸡数据没有卡到这里,这里的做法我也理解的不太深刻,不需要的同志们可以直接跳过。
我的数学老师常说学理科要细腻,那我们就来看看,我们刚才的思路真的无懈可击了吗?
来看下面这组数据:
1 4 7 3 aaaaaaa aaa aaa aaa如果按照我们刚才所说的思路,枚举每一个双旋转字符串,我们发现都是 ,总数为 。按照我们刚才比对的思路,每一个双旋转字符串的前缀和后串的前缀都是相等的 ,那么我们在 中匹配的字符串都是 ,也就说明这 个双旋转字符串对答案的贡献都是 ,最终答案是 。
但是很显然,正确答案是 。问题应该很明显了,因为我们双旋转字符串重合了,导致了不合法情况出现。
如何防止不合法情况出现?我们要判重。那么显然我们会想到每次枚举后将这个字符串记录下来,下次再枚举的时候查找是否已经出现过这个字符串即可。
考虑实现。可能很多人又会想到用 set 这类 STL 来完成,但是我通过实践,T 四个点(当然吸氧能过)。对于 的数据,显然如果算法时间复杂度是 级别会非常吃紧,如果常数很大会直接 T 飞。那么我们要尽量找到 的算法,也就证明这里的判重需要是 。
有人又会想到用 unordered_map,我也试过,依然是 T 四个点(有一个点从 )。为什么?我们要注意 unordered_map 平均复杂度才是 。最坏情况可以达到 。当然,这种情况概率非常小,但是如果两个 unordered_map 这种情况出现的次数就会增加,就可能导致我们的代码被卡掉。
后来我在写题解的时候灵光一现,想到了再哈希一次的做法。我们选取一个空间能开下的大模数,并建立一个判重数组,对于每个哈希过的字符串,将它的哈希值取模后存入判重数组,用的时候比对就好。
当然,这种做法存在不严谨性。如果两个不同哈希值模数相同,就会导致对答案的贡献缺失。一种解决办法是双哈希,能保证正确性,但是太麻烦了弱弱的我也懒得写,如果有大佬有兴趣可以尝试。我的方法是就找一个大模数,而且是质数,剩下的就是看运气了。具体实现看代码。
复杂度分析
注意:我们将 , 引用为 ,。
-
对于读入后的预处理,我们要把 中的所有字符串哈希并存入一个 unordered_map,根据 unordered_map 的平均复杂度 ,推得这一步的复杂度是 。
-
预处理三个快速幂, 我们近似为一个常数,可以忽略,不计入总复杂度。
-
对于计算答案,我们要枚举 中的所有字符串,对每个字符串倍长哈希后遍历一遍,比对后还要 判重,之后 查找 中的贡献,所以最后的复杂度是 。
所以最后的总复杂度大概是是 。当然还有很大的常数和 unordered_map 的不稳定性。
代码
思路都懂,细节都理解,其实代码就能自己写出来了。有一些具体实现细节见代码中的注释。
/* 其实代码好像还挺简单的hhhh */ #include <iostream> #include <algorithm> #include <cstring> #include <string> #include <unordered_map> using namespace std; typedef unsigned long long ull; const int maxtot = 20005; const int maxm = 4e6+5; const int base = 131; //基底 const int mod = 19260817; //判重模数,不会有人卡这个吧? string S[maxtot], T[maxtot]; int totalT, totalS, n, m; int mid;//前后串的长度 ull Pow[maxm];//预处理基底的幂,其实只用3个 unordered_map<ull,int> hashT; //存储T的所有字符串 ull Hash[maxm]; //求双旋转字符串的哈希数组 int cnt[mod]; //判重数组 ull qmi(ull a,ull b){//快速幂,ull自动溢出取模 ull res = 1; while (b){ if (b & 1) res *= a; a *= a; b >>= 1; } return res; } ull make_hash(string s, int len){//一次性哈希 ull res = 0; for (int i = 0; i < len; i ++){ res = res*base + s[i]; } return res; } ull get_hash(int l,int r){//需要反复查找的哈希值 return Hash[r] - Hash[l-1]*Pow[r-l+1]; } int deal(string s, int len, int t){//计算贡献 int res = 0, length = len-mid; /* substr大法吼啊! */ string temp = "0"; temp += s.substr(0,mid); temp += s.substr(0,mid); for (int i = 1; i <= mid<<1; i ++){ Hash[i] = Hash[i-1]*base + temp[i]; } ull hashVal = make_hash(s.substr(mid,len-mid), len-mid);//后串前缀的哈希 for (int i = 1, j = mid; i <= mid; i ++, j ++){ /* 判重。常数大了1倍,想要快的可以直接删掉 */ if (cnt[get_hash(i, j)%mod] == t){ /* 改用int赋值,就不用memset恶心人了 */ continue; } cnt[get_hash(i, j)%mod] = t; /* ———————————————————————————————— */ if (get_hash(i, i+length-1) == hashVal){//如果求得两前缀相等 res += hashT[get_hash(i+length, j)];//统计匹配串的答案 } } return res; } int main(){ ios::sync_with_stdio(false); cin.tie(0), cout.tie(0); cin >> totalS >> totalT >> n >> m; for (int i = 1; i <= totalS; i ++){ cin >> S[i]; } for (int i = 1; i <= totalT; i ++){ cin >> T[i]; } mid = (n+m) >> 1; /* 预处理我们需要的三个base的幂 */ Pow[mid] = qmi(base,mid), Pow[m] = qmi(base,m), Pow[(n-m)>>1] = qmi(base,(n-m)>>1); /* 对T中的所有字符串哈希 */ for (int i = 1; i <= totalT; i ++){ /* 就想用数组一样用 unordered_map */ hashT[make_hash(T[i], m)] ++; } int ans = 0; for (int i = 1; i <= totalS; i ++){ ans += deal(S[i], n, i);//累加答案 } cout << ans << endl; return 0; }总结
终于把这篇题解写完了。可能会比较啰嗦,也可能会有错误,欢迎指出!
写这篇题解收获真的挺大的,我一开始 T 四个点吸氧就满意了,后来不断思考,最后正式通过了,大概交了 40 多遍。
还有就是希望管理修一下题面,加几组 hack,免的再耽误后人。
-
- 1