1 条题解
-
0
自动搬运
来自洛谷,原作者为

Orion545
**搬运于
2025-08-24 21:46:01,当前版本为作者最后更新于2018-04-23 15:26:38,作者可能在搬运后再次修改,您可在原文处查看最新版自动搬运只会搬运当前题目点赞数最高的题解,您可前往洛谷题解查看更多
以下是正文
广告
思路
0x01 KMP
一个非常显然而
优秀的想法:把模板串按照'*'分段,然后对于每一段求,'?'就当成可以对于任意字符匹配就行了对于每个文本串,从前往后找第一个可以匹配的地方,可以证明,一段字符越靠左,结果一定越优
找到了一个匹配位置以后往后跳,同时换成更新的一段模板串,一直匹配到模板串没有了为止
听起来很不错,是吗?代码看着也很简fu洁za:
#include<iostream> #include<cstdio> #include<cstring> #include<algorithm> using namespace std; int cmp(char l,char r){ if(l=='?'||r=='?') return 1; return l==r; } void getfail(char s[],int fail[]){ int len=strlen(s),i,j=0; fail[0]=fail[1]=0; for(i=1;i<len;i++){ while(j&&!cmp(s[i],s[j])) j=fail[j]; j+=cmp(s[i],s[j]);fail[i+1]=j; } } int match(char b[],char a[],int fail[],int l,int r,int m,int n){ int i,j=0; for(i=l;i<=r;i++){ while(j&&!cmp(b[j],a[i])) j=fail[j]; j+=cmp(b[j],a[i]); if(j==m) return i; } return -1; } void empty(){} char s[100010],b[15][100010],a[100010];int n,m,cnt,p1,p2,fail[15][100010],tot; int main(){ scanf("%s",s);int i,j,tmp,Q,k,l,r,ans=0;n=strlen(s); p1=(s[0]!='*');p2=(s[n-1]!='*'); for(i=0;i<n;i++){ if(s[i]=='*') continue; j=i;tmp=0;cnt++;b[cnt][tmp]=s[j]; while(s[j+1]!='*'&&j<n) j++,tmp++,b[cnt][tmp]=s[j]; i=j; } for(i=1;i<=cnt;i++) getfail(b[i],fail[i]),tot+=strlen(b[i]); if(cnt==0){ scanf("%d",&Q); for(j=1;j<=Q;j++){ scanf("%s",a);puts("YES"); } } if(cnt==1&&p1&&p2){ scanf("%d",&Q); for(j=1;j<=Q;j++){ scanf("%s",a);m=strlen(a); if(m!=strlen(b[1])) continue; l=match(b[1],a,fail[1],0,m-1,strlen(b[1]),m); if(l==m-1) puts("YES"); else puts("NO"); } return 0; } scanf("%d",&Q); for(j=1;j<=Q;j++){ scanf("%s",a);m=strlen(a);bool flag=0; if(m<tot) goto end; l=p1*strlen(b[1]);r=m-p2*strlen(b[cnt])-1; if(p1) for(i=0;i<strlen(b[1]);i++) if(!cmp(b[1][i],a[i])) goto end; if(p2) for(i=0;i<strlen(b[cnt]);i++) if(!cmp(b[cnt][i],a[m-strlen(b[cnt])+i])) goto end; for(k=p1+1;k<=cnt-p2;k++){ l=match(b[k],a,fail[k],l,r,strlen(b[k]),strlen(a)); if(l==-1) goto end; l++; } puts("YES");flag=1; end:if(!flag) puts("NO"); } }
凉!凉!
为什么呢?好像我们把'?'当成通配符处理,也没有违背数组的意义啊?
是的,这个做法的确没有违背,但是有一点:我们无法通过传统的方法求出数组
我们看一下求的代码:
bool cmp(char l,char r){//带通配符情况下判断相等 if(l=='?'||r=='?') return 1; return l==r; }j=0;fail[0]=fail[1]=0;//fail就是next for(i=1;i<len;i++){ while(j&&!cmp(s[i],s[j])) j=fail[j]; j+=cmp(s[i],s[j]);fail[i+1]=j; }这其中,为什么变量可以直接不更新直接使用?(其他版本的的本质上其实也没有更新)
因为这里的“公共前后缀”有一个前提条件:每个字符的意义不变,这样才能满足我们一次一次往后推的过程中,利用的都是最长的已知公共前后缀;如果中间出现意义不统一的字符的话,就会导致
但是'?'这个字符显然不满足这一条件——它可能在中作为'a',但是在中作为'b',这就会导致不能直接继续调用,所以在本题中,这个求的方法是错误的(20分已经是出题人怜悯我们了)
那么怎么办?难道暴力求吗?那样可是的,还不如暴力匹配呢......
别急,我们考虑优化这个的正确性
0x02 优化の
分段这个思想,在上一步中并未出现任何问题
那我们考虑把分段贯彻到底——把'?'也分开!
这样我们会得到一堆不包含任何通配符的字符串,依旧是按照上面的方法,我们分段求,求最靠左的匹配......
代码如下:
// luogu-judger-enable-o2 #include<iostream> #include<cstdio> #include<cstring> #include<algorithm> using namespace std; int fail[15][100010],n,m,cnt=0,jump[15],stl[15]; char b[15][100010],a[100010]; void getfail(char s[],int len){ int i,j=0;fail[cnt][0]=fail[cnt][1]=0;stl[cnt]=len; for(i=1;i<len;i++){ while(j&&(s[i]!=s[j])) j=fail[cnt][j]; j+=(s[i]==s[j]);fail[cnt][i+1]=j; } } char s[100010]; int main(){ scanf("%s",s);int i,j,len,k,l;m=strlen(s); for(i=0;i<m;i++){ if(s[i]=='*') continue; if(s[i]=='?'){jump[cnt]++;continue;} j=i;cnt++;len=0; while(s[j]!='*'&&s[j]!='?'&&j<m) b[cnt][len]=s[j],j++,len++; getfail(b[cnt],len); i=j; } scanf("%d",&n); for(l=1;l<=n;l++){ scanf("%s",a);len=strlen(a); i=jump[0];bool flag=1; for(k=1;k<=cnt;k++){ j=0; for(;i<len;i++){ while(j&&(a[i]!=b[k][j])) j=fail[k][j]; j+=(a[i]==b[k][j]); if(j==stl[k]) break; } if(j<stl[k]){ puts("NO");flag=0;break; } i+=jump[k]; } if(flag) puts("YES"); } }
怎么还是
等等,这个算法......有一个问题:靠左的匹配,现在一定是最优的了么?
不是!
我们考虑一个例子:
模板串是
文本串是
那么,显然第一个分段的第一个匹配就是最左边的那个,但是在这种情况下,我们的算法会显示没有匹配——因为'?'只能匹配一个字符,所以这时可能靠右才是更好的选择
这样来看,好像走到死胡同了,接下来怎么办呢......
0x03
行不通了,我们来想想一个更基础的做法:
题目中说了,本题的通配符只有10个最多,这意味着我们可以以通配符为界,设定状态(其实上面的两个算法都没有考虑到这个问题......省选题可不是忽略了一个条件也能轻松的)
设表示文本串的前个字符匹配了模式串第个通配符(包括这个通配符)前面的所有字符,值为0代表不能,值为一代表不行
那么,显然有两种转移:第个通配符是'*'或者'?'
转移的条件,是从第个字符开始的一段字符串可以与第个和第个通配符之间的模板串字符匹配
设这一段模板串长度为
如果是'?',那么
如果是'*',那么
这个递推貌似是对的,但是有一个问题:
怎么足够快地知道,从第个字符开始的一段字符串,与第个和第个通配符之间的模板串字符,可不可以匹配???
0x04 字符串
古话说的好,转换思路是最重要的(貌似不是古话?=_=)
我们看,如果想知道两个字符串,而且在这种情况下是两个已知的字符串,那么怎么判断他们是否匹配(等价于是否相等)?
一下!
我们如果知道了这两段字符串的值,那么判断它们是否相等不是轻而易举了?
先别急着高兴,因为求一段未知字符串的值也是的......
然而我们的程序需要在这一步上只能有的时间开销
怎么办?
0x05 前缀和
想一想,我们在需要知道一段区间的和(就是值)的时候,是怎么做的?
前缀和啊!
但是,值,真的可以前缀和吗?
完全大丈夫!
我们考虑一个字符串的常见过程:
以字符串的第i项,作为的系数,然后把选定的(比如19260817)代入得到值,中间通过mod一个数或者Unsigned类型的自然溢出来减小范围
也就是说这个过程实际上是多项式求值,秦九韶算法优化下可以达到
再考虑一个已知字符串,设它的长度为
那么,它的前缀的字符串的值,就是这样的一个表达式:
考虑另一个值,算法也是一样的(设)
那么怎么求到这段字符串的值呢?
我们令,把和展开,就会得到:
把子串提取出来作为,长度
那么:
正好就是这个子串的值
因此我们把输入的文本串的前缀的值预处理好,同时预处理出的幂,就可以完成判断了
代码如下:
#include<iostream> #include<cstdio> #include<cstring> #include<algorithm> #define ll unsigned long long ll key=19260817ll;//膜法数字 using namespace std; ll pre[100010],mul[100010],h[20];int n,cnt,sp[20],stl[20],dp[15][100010]; //sp表示通配符类型,stl就是strlen(表示某一段的长度),h是模板串某一段的hash值 char b[15][100010],a[100010],tmp[100010]; ll gethash(char s[],int len){//秦九韶算法求hash ll re=0;int i; for(i=0;i<len;i++) re*=key,re+=(ll)s[i]; return re; } int main(){ scanf("%s",a);int i,j,k,l,len=strlen(a);ll t1; mul[0]=1; for(i=1;i<=100000;i++) mul[i]=mul[i-1]*key; if(a[0]=='*'||a[0]=='?') h[++cnt]=gethash(b[cnt],stl[cnt]=0); for(i=0;i<len;){//预处理每一段 if(a[i]=='*'||a[i]=='?'){sp[cnt]=(sp[cnt]||(a[i]=='*'));i++;} j=0;cnt++; while(a[i]!='*'&&a[i]!='?'&&i<len) b[cnt][j]=a[i],i++,j++; h[cnt]=gethash(b[cnt],stl[cnt]=j); } len++; if(a[len-2]=='*'||a[len-2]=='?') cnt++,sp[cnt]=stl[cnt]=h[cnt]=0; else sp[cnt]=0; scanf("%d",&n); for(l=1;l<=n;l++){ memset(a,0,sizeof(a)); scanf("%s",a);a[strlen(a)]='$'; memset(dp,0,sizeof(dp));dp[0][0]=1; len=strlen(a); for(i=0;i<len;i++) pre[i+1]=pre[i]*key+(ll)a[i];//求前缀和 for(j=0;j<=len;j++){ for(i=0;i<=cnt;i++){ if(!dp[i][j]) continue; t1=pre[j+stl[i+1]]-pre[j]*mul[stl[i+1]]; if(t1==h[i+1]){//hash值相等,匹配成功 if(sp[i+1]) for(k=j+stl[i+1];k<=len;k++) dp[i+1][k]=1; else dp[i+1][j+stl[i+1]+1]=1; //这里分情况递推 } } } if(dp[cnt][len]) puts("YES"); else puts("NO"); } }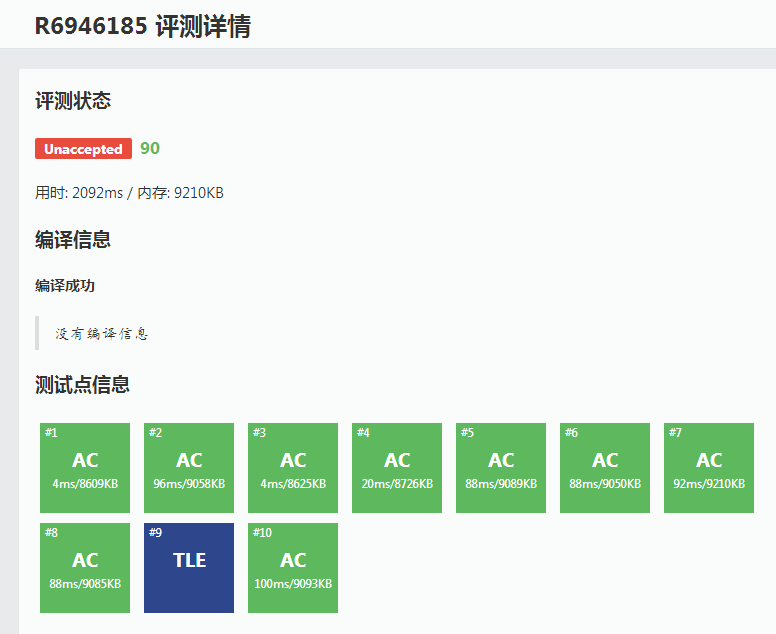
难道这个算法还是错的????
0x06 最后的优化
不能放弃希望
我们观察写出的代码——没有任何一个地方会造成死循环,那么就是常规循环导致它了,究竟是哪一段呢?
if(t1==h[i+1]){ if(sp[i+1]) for(k=j+stl[i+1];k<=len;k++) dp[i+1][k]=1; else dp[i+1][j+stl[i+1]+1]=1; }没错,正是这个万恶的循环!
这个循环的作用,是在,也就是下一个通配符为'*'的时候,用来一路更新下去的
但是这样更新来更新去,一定会导致
那我们需要一个优化,让这个循环的过程分散到遍历的时候去,省去一层的复杂度
这里,我们考虑使用不同的值来表示的不同意义:
当的时候,说明这个节点没有访问过,continue
当的时候,说明这个节点被且仅被一个'?'往后的递推访问过,这时我们令,并continue(因为当前节点并没有意义,只是访问过,不能继续递推)
当的时候,说明这个节点是被'*'访问过的,这时我们令,并且这个点有意义,可以往下递推
当的时候,说明这个节点被'?'访问过的节点更新到了2,这时直接从这个节点往后递推,不需要更新值
最后,当的时候——这个是一个非常特殊的情况
我们发现,上述的-1到2的值里面,1的优先级最高,0次之,2最低,-1可以被它们随便覆盖
但是我们的确会出现这样的情况:一个0延伸出来的2,覆盖到了另一个0
此时这个0不仅会令,它自身也需要往下递推,而不是直接continue(因为上一个过来的2说明它有这个意义)
所以我们令这种情况下的的值为3,此时令,并且从当前节点递推
初始化的时候,全部设为-1,
最后如果dp[模板串的段数][文本串长度]不是-1的话,就输出YES,否则NO
代码如下:
#include<iostream> #include<cstdio> #include<cstring> #include<algorithm> #define ll unsigned long long ll key=19260817ll; using namespace std; ll pre[100010],mul[100010],h[20];int n,cnt,sp[20],stl[20],dp[15][100010]; char b[15][100010],a[100010],tmp[100010]; ll gethash(char s[],int len){ ll re=0;int i; for(i=0;i<len;i++) re*=key,re+=(ll)s[i]; return re; } int main(){ scanf("%s",a);int i,j,k,l,len=strlen(a);ll t1; mul[0]=1; for(i=1;i<=100000;i++) mul[i]=mul[i-1]*key; if(a[0]=='*'||a[0]=='?') h[++cnt]=gethash(b[cnt],stl[cnt]=0); for(i=0;i<len;){ if(a[i]=='*'||a[i]=='?'){sp[cnt]=(sp[cnt]||(a[i]=='*'));i++;} j=0;cnt++; while(a[i]!='*'&&a[i]!='?'&&i<len) b[cnt][j]=a[i],i++,j++; h[cnt]=gethash(b[cnt],stl[cnt]=j); } len++; if(a[len-2]=='*'||a[len-2]=='?') cnt++,sp[cnt]=stl[cnt]=h[cnt]=0; else sp[cnt]=0; scanf("%d",&n); for(l=1;l<=n;l++){ memset(a,0,sizeof(a)); scanf("%s",a); len=strlen(a);a[len]='$';len++; memset(dp,-1,sizeof(dp));dp[0][0]=2;pre[0]=0; for(i=0;i<len;i++) pre[i+1]=pre[i]*key+(ll)a[i]; for(j=0;j<=len;j++){ for(i=0;i<=cnt;i++){//只有这里有差别 if(dp[i][j]==-1) continue; if(dp[i][j]==1) dp[i][j+1]=1; if(!dp[i][j]){ dp[i][j]=2; if(dp[i][j+1]==-1) dp[i][j+1]=2; if(dp[i][j+1]==0) dp[i][j+1]=3;//判断赋2还是3 continue; } if(dp[i][j]==3){ dp[i][j]=2; if(dp[i][j+1]==-1) dp[i][j+1]=2; if(dp[i][j+1]==0) dp[i][j+1]=3;//判断赋2还是3 } t1=pre[j+stl[i+1]]-pre[j]*mul[stl[i+1]]; if(t1==h[i+1]){ dp[i+1][j+stl[i+1]]=max(dp[i+1][j+stl[i+1]],sp[i+1]); } } } if(dp[cnt][len]!=-1) puts("YES"); else puts("NO"); } }
Finally,这道题目告一段落
0x07 总结
一没注意,题解就写了两百多行了
这的确做起来是道麻烦但是有趣的题目,最后算法返璞归真,用最基础的、洛谷上普及-的字符串哈希就做完了
但是整个做题的过程却非常耐人寻味:KMP为什么是错的?怎么实现一个看起来不可能的过程?为什么满足前缀和?怎么保证时间复杂度的情况下把递推正确性保证......
虽然最后的代码跑的很慢,但是这并不意味着做完这道题我的收获就小
恰恰相反,那长达一整页的提交记录才是真正得到的、最珍贵的思维
- 1