1 条题解
-
0
自动搬运
来自洛谷,原作者为

10000point
AFO | Stay hungry, stay foolish.搬运于
2025-08-24 21:32:22,当前版本为作者最后更新于2022-06-23 20:37:52,作者可能在搬运后再次修改,您可在原文处查看最新版自动搬运只会搬运当前题目点赞数最高的题解,您可前往洛谷题解查看更多
以下是正文
本来不打算写题解的,但我发现洛谷上几乎没有一篇题解对本题进行了系统的分析,很多题解的方法都是因数据水和本题的特殊性质才过的,所以就写了本篇详细的题解。
思路
首先,对于每一个 我们可以向 ,,, 分别连边,于是问题转化为我们要求一种方案,使每一个 需对应一个它连向的 ,很明显是二分图匹配。
如果不能够完美匹配,就直接无解。
否则若不用求字典序最小就很简单。但因为要求字典序最小,我们就考虑新匹配一个的影响。首先肯定要从小到大枚举他的儿子(字典序最小),如果有没匹配的,就直接匹配。否则我们必须去抢一个已经匹配的。这样可以保证现在匹配这个点字典序一定最优,但不能保证抢的点以及增广路上的其它点最优。而一个序列的字典序是从前往后比较的,也就是我们需要保证前面的最优。于是我们倒着匹配,就可以完成本题了。
思考(重点)
但其实在二分图完美匹配中直接倒着匹配是不能保证字典序最小的,只是因为本题有特殊性质——每个左边的点只会有两条边与之相连。这是为什么呢?我们将从三个问题对此分析。
1.为什么在二分图完美匹配中直接倒着匹配不能保证字典序最小?
这是我在知乎上找到的一张图:
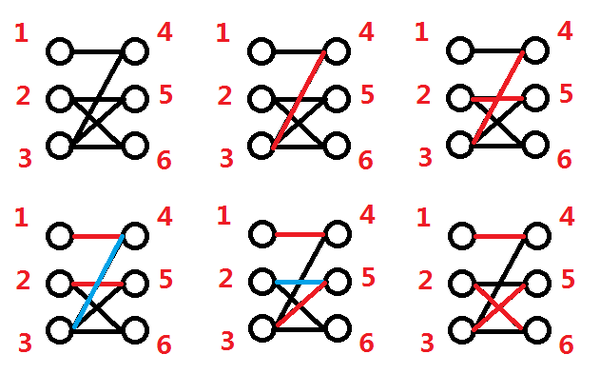
由图可见,在第五步寻找增广路时, 去抢了 所匹配的 ,但 的优先级是高于 的。推广可知,虽然倒着匹配可以保证当前的最小,但因为有后效性,后面的增广路可能会交叉,导致顺序被打乱。所以二分图完美匹配中直接倒着匹配是不能保证字典序最小的。
2.为什么在每个左边的点最多只有两条边与之相连的二分图完美匹配中直接倒着匹配能保证字典序最小?
这是一个很巧妙的证明,来自 byvoid 大佬。
首先,我们不停地选择右边只有一条连边的点。由于要达到完美匹配,与它相连的左边的点必须与它匹配。所以可以把那个点连的两条边删掉。
此时,所有右边度数为 的点都被删完了,所以 。而右边总度数开始时为 ,每匹配一个点度数 ,所以假设剩下 个点,总度数一定为 ,又因为 ,所以每个右边的点度数都为 。
然后因为图中每个点度数都为 ,所以被分成了若干个度数为 的环。倒着匹配的过程中,确定了一个匹配后,两个端点所连的另两个点的匹配也就确定了,一直循环下去,环中所有剩余的匹配也就确定了(自己模拟一下有助于理解)。所以虽然有后效性,但在后面的过程中只有一种选择,就一定可以保证字典序最小了。
3.为什么本题中每个左边的点只会有两条边与之相连?
看似对于每一个 我们可以向 ,,, 分别连边,这样每个左边的点可能会有四条边与之相连。但实际上, 和 肯定只会有一个在 至 范围内, 和 也一样,所以每一个点都可以排除两种情况,以至本题中每个左边的点只会有两条边与之相连。
现在,我们已经解决了这三个问题了。但对于一般的二分图完美匹配,求最小字典序的通解是什么呢?
算法 1:
枚举全排列,再看能否完美匹配。时间复杂度 。
算法 2:
从前往后枚举,对于每一个点,从小到大假设它与谁匹配,如果它匹配后剩下的图仍构成完美匹配,就说明它可以与当前儿子匹配,删掉这个点与其匹配点。时间复杂度 。
算法 3:
在算法 2 中,每假设当前点 与某个点 匹配,就要对整个图跑一次二分图匹配,但实际上大多点在这次匹配操作后是没有影响的。所以我们可以先在开始时对整个图跑一次二分图匹配。经过分析,我们可以发现把 与 匹配只会影响两个点:目前与 匹配的点与目前与 匹配的点。所以每次只用对影响的这两个点中的任意一个点跑一次增广路就可以了。时间复杂度 。
至此,我们已经找到了在较低时间复杂度内对一般的二分图完美匹配求最小字典序的方法了。对于不是完美匹配的,需要通过网络流实现,由于我还没学网络流,所以无法在此展开叙述。
代码
倒着匹配的方法:
#include<bits/stdc++.h> using namespace std; const int M=1e4+5; int n,m,x[M],ans,linkx[M],linky[M]; bool vis[M]; vector<int> son[M]; int dfs(int k) { if(vis[k]==1) return 0; vis[k]=1; for(int a=0;a<son[k].size();a++) { int s=son[k][a]; if(linky[s]==0||dfs(linky[s])==1) { linkx[k]=s; linky[s]=k; return 1; } } return 0; } int main() { scanf("%d",&n); for(int a=1;a<=n;a++) scanf("%d",&x[a]); for(int a=1;a<=n;a++) { if(a+x[a]<=n) son[a].push_back(a+x[a]); if(a-x[a]>=1) son[a].push_back(a-x[a]); if(a+n-x[a]<=n) son[a].push_back(a+n-x[a]); if(a-n+x[a]>=1) son[a].push_back(a-n+x[a]); if(son[a].size()!=0) sort(son[a].begin(),son[a].end()); } for(int a=n;a>=1;a--) { memset(vis,0,sizeof(vis)); ans+=dfs(a); } if(ans<n) { printf("No Answer\n"); return 0; } for(int a=1;a<=n;a++) printf("%d ",linkx[a]-1); }通解:
#include<bits/stdc++.h> using namespace std; const int M=1e4+5; int n,m,x[M],ans,linkx[M],linky[M]; bool vis[M],exi[2*M]; vector<int> son[M]; int dfs(int k) { if(vis[k]==1||exi[k]==0) return 0; vis[k]=1; for(int a=0;a<son[k].size();a++) { int s=son[k][a]; if(exi[n+s]==0) continue; if(linky[s]==0||dfs(linky[s])==1) { linkx[k]=s; linky[s]=k; return 1; } } return 0; } int main() { scanf("%d",&n); for(int a=1;a<=n;a++) scanf("%d",&x[a]); for(int a=1;a<=n;a++) { if(a+x[a]<=n) son[a].push_back(a+x[a]); if(a-x[a]>=1) son[a].push_back(a-x[a]); if(a+n-x[a]<=n) son[a].push_back(a+n-x[a]); if(a-n+x[a]>=1) son[a].push_back(a-n+x[a]); if(son[a].size()!=0) sort(son[a].begin(),son[a].end()); } for(int a=1;a<=2*n;a++) exi[a]=1; for(int a=1;a<=n;a++) { memset(vis,0,sizeof(vis)); ans+=dfs(a); } if(ans<n) { printf("No Answer\n"); return 0; } for(int a=1;a<=n;a++) { for(int b=0;b<son[a].size();b++) { int s=son[a][b]; bool check=0; if(linkx[a]==s) check=1; else { exi[a]=exi[n+s]=0; linky[linkx[a]]=0; memset(vis,0,sizeof(vis)); if(dfs(linky[s])==1) check=1; else linky[linkx[a]]=a; exi[a]=exi[n+s]=1; } if(check==1) { exi[a]=exi[n+s]=0; printf("%d ",s-1); break; } } } }
- 1